Informationsmodellens uppgång, fall och återkomst. Och sedan?
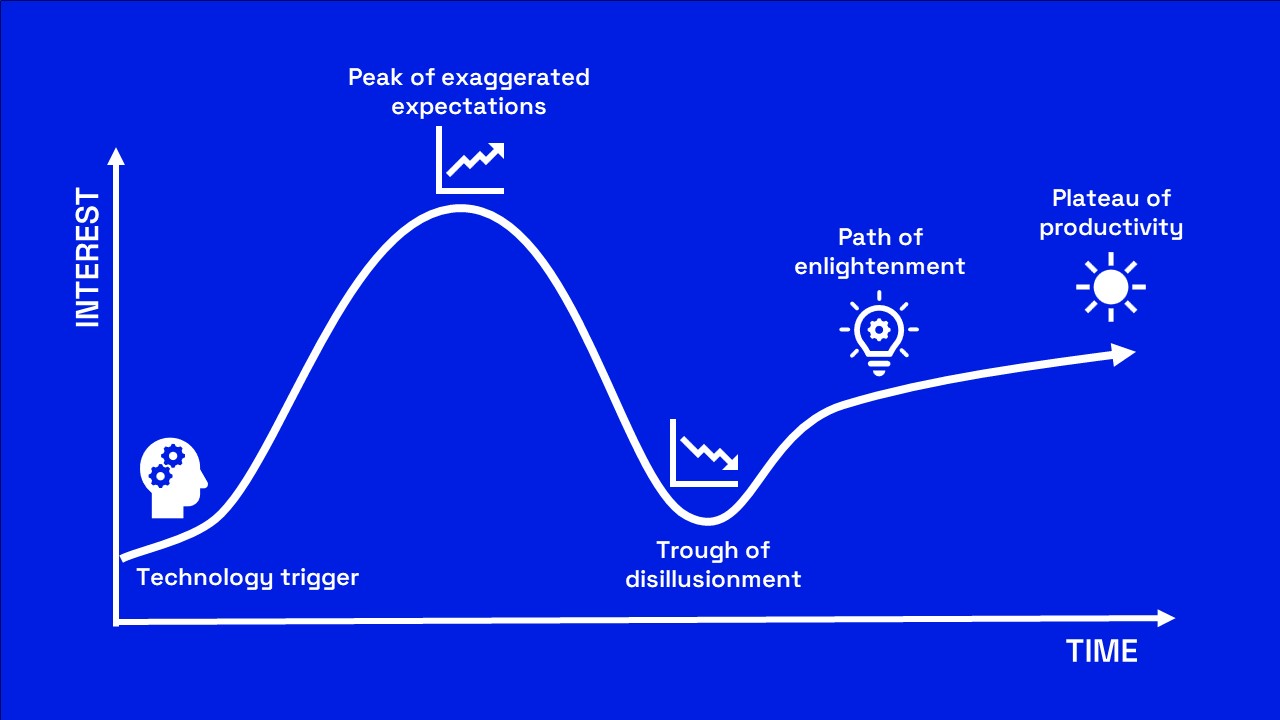
Informationsmodelleringen har gjort en resa från självklar nödvändighet till bortglömd, och nu ser vi dess renässans. Driven av behovet av datahantering och Big data har informationsmodellering hamnat i fokus igen. Men vad händer efter att dagens hajp peakat? Oftast följs en peak av en backlash.
/Peter Tallungs, IRM 2023-11-02
Är vi nära peaken nu?
Just nu efterfrågas informationsmodellering som aldrig förr, liksom informationsarkitekter och andra roller inom datahantering. Det är en våg som varit på gång länge och som just nu rullar in med full kraft. Behovet har egentligen funnits hela tiden, det är bara medvetenheten som saknats. Men nu är intresset större än någonsin och tycks växa för varje dag som går.
Hur allt började
Hur kan vi förstå hur efterfrågan på informationsmodellering kan ha genomgått radikala skiften, från att vara en grundbult inom it- och verksamhetsutveckling till att bli bortglömt, för att sedan återigen bli i ropet? Låt oss ta en resa tillbaka i tiden och se vad som hände.
I it-branschens barndom, på 70- och 80-talen, var det självklart att man tog fram informations- eller datamodeller, det var en grundbult inom it-utveckling.
(Det hette förstås inte ”it” förrän i början av 90-talet. Det var först då man började tala om informationsteknik. Det vi höll på med kallades ADB, Automatisk databehandling eller ibland uttalat som Administrativ databehandling.)
Från början hade datamodellering endast handlat om att designa databaser. Emellertid började en insikt växa fram; att man kunde använda samma typ av modeller för att beskriva en aspekt av verksamheten, det vill säga den data som verksamheten behöver hantera och de företeelser som dessa data i sin tur representerar.
År 1982 grundades vårt företag IRM med syftet att lyfta fram informationsperspektivet inom verksamhetsutveckling. Vårt företagsnamn IRM, som står för Information Resource Management, speglar detta synsätt och betonar betydelsen av att vårda verksamhetens information som en värdefull resurs. Då räcker det inte med informationsmodellering förstås, men det är en nödvändig början, att kartlägga den information man har och behöver hantera. Ty man kan inte förvalta och utveckla det man inte har en förståelse för och tydligt kan benämna och definiera.
Nedgången på 90-talet
Under mitten av 1990-talet märkte vi en plötslig och drastisk minskning av intresset för informationsmodellering. Jag har alltid tänkt att orsaken var två nya modelleringssätt, Processmodellering och Objektorienterad programvarudesign som just då fick stora genomslag. Informationsmodellering upplevdes som överspelad både inom verksamhets- och systemutveckling.
90-talstrend 1: Processmodellering
Under 90-talet blev modellering av verksamhetsprocesser mycket populärt. Och det till den grad att verksamhetsmodellering snart blev helt synonymt med processmodellering. Detta perspektiv på en verksamhet slog ut andra perspektiv och räckte tyckte man.
Detta är själva definitionen på en hajp, att en metod, teknik eller aspekt blir så populär att den blir fullständigt dominerande och tränger ut alla andra synsätt.
Typiskt för verksamhetsutvecklare jag mötte på den tiden var att de påstod att de redan hade modellerat hela sin verksamhet. Men när jag bad att få se modellerna, var det endast processmodeller. Alla termer i modellerna var odefinierade, och kunde betyda lite vad som helst. Dessutom, mycket av det man kallade processer var i själva verket vad vi idag skulle kalla för verksamhetsförmågor. Modellerna var i stort sett oanvändbara. De skrapade på ytan och dolde den underliggande komplexiteten som alltid finns och som behöver lyftas fram och hanteras.
Mot slutet av 90-talet hade det gått så långt att en kollega till mig, en skicklig modellerare och verksamhetskonsult, hävdade att han hade helt slutat att informationsmodellera. För när han visade en informationsmodell för verksamhetsfolk nickade de bara utan några åsikter eller dialog. Däremot, när han presenterade en processmodell, var engagemanget helt annorlunda. De var aktiva, korrigerade och ställde frågor. Han drog slutsatsen att processmodeller var det man kunde kommunicera med, men inte med informationsmodeller, och därför var enbart processmodeller användbara.
Många år senare påminde jag kollegan om vad han sagt då på 90-talet. Han svarade förvånad: ”Har jag verkligen sagt det? Så fel! Att det är svårt att nå fram med informationsperspektivet betyder inte att det inte är nödvändigt. Tvärtom, det innebär att vi måste anstränga oss mer och utveckla hur vi arbetar med modellerna.”
90-talstrend 2: Objektorienterad programvarudesign
Den andra anledning till informationsmodelleringens tillbakagång på 90-talet som jag vill lyfta fram är kopplad till ett paradigmskifte inom systemutveckling. Fram till mitten av 90-talet strukturerade man så att man tydligt skilde på datastrukturer och programlogik.
Datastrukturen fanns i databasen som designades med hjälp av datamodellering, så den naturligt avbildade den data som verksamheten hanterade. Datastrukturen i databasen blev då vad man kan kalla en domänmodell, vilket betyder att den avbildade den verksamhetsdomän som applikationen skulle hantera. Sedan fanns all hantering i programkoden, som var proceduriellt strukturerad. Med andra ord, databasen avbildade vad som hanterades, medan programkoden definierade hur hanteringen utfördes, det vill säga vad som gick att göra med informationen.
90-talets andra halva slog ett nytt paradigm igenom: objektorienterad design av programkod, med programmeringsspråk som stödde det synsättet. Man skulle inte längre på samma sätt skilja på data och programlogik. Programkoden strukturerades kring domänklasser som exempelvis ”Kund”. En ”Kund” blev då en ”klass,” en modul i koden som inte bara representerade data (såsom kundens egenskaper som kundnummer, kundnamn, och kundstatus) utan även dess beteende (det vill säga vilka åtgärder som kunde utföras med en kund, såsom uppdatera, ta bort, fakturera med mera). Data lagrades fortfarande i databasen, men blev mer indirekt för programmeraren. Databasens uppgift sågs som mycket mer mekanisk, att persistera objektens tillstånd mellan programexekveringar.
Domänmodellen flyttade på så vis in i programkoden och blev också mer fullständig, eftersom den inte bara uttryckte vilka egenskaper objekt av en viss klass kunde ha, utan även vad som kunde utföras med objektet.
Idag är objektorientering den helt dominerande paradigmen inom programutveckling, och det med all rätt. Det är ett oerhört kraftfullt sätt att med programkod modellera domänen. Objektorienterad programdesign är så självklar att man idag aldrig ens nämner att det är det man gör.
Men just då på 90-talet, när objektorienteringshajpen var på sin höjdpunkt så var det som det så ofta blir. När något nytt helt fyller alla med stora förväntningar vill man gärna förkasta allt gammalt. Datamodellering blev särskilt utsatt eftersom den av många fortfarande betraktades som en metod för att designa databaser.
Vad man då inte såg var att objektorientering i själva verket bara var en utveckling av det perspektiv som datamodellering ger. Data- och informationsmodellering ger en domänmodell med domänens entiteter, det vill säga klasser, i centrum med deras egenskaper och relationer. Detsamma gör domänmodellen i objektorienterad programkod. Skillnaden är att den senare även inkorporerar objektens beteenden i samma struktur.
Jag brukar tänka på objektorienteringshajpen på 90-talet (som jag själv var en entusiastisk del av) som ett fadersuppror. Man har ett behov av att göra saker annorlunda än den äldre generationen. Men i grunden är man mer lik sin far än man vill erkänna.
Under 00-talet, när jag talade med lite äldre branschkollegor om att man hade slutat datamodellera, fick jag höra: ”På vår tid datamodellerade vi alltid när vi byggde applikationer. Det var den viktiga modellen, den allt handlade om. Utan en datamodell klarade man sig inte. Men sen kom ju objektorientering och vi fick höra att datamodellering inte längre behövdes. Förstår inte varför, men vi fick höra att datamodellering nu var överspelat.”
I själva verket var modellering av domänen fortfarande lika viktig, fast man trodde att det skulle kunna göras i koden bara, av programmerare och för programmerare endast, och inte synligt och gemensamt för alla inblandade. Med resultat att vi förlorade ett par årtionden av gemensam kunskapsuppbyggnad inom våra verksamheter, runt information, begrepp inom verksamhetens domän.
Det har också hindrat utvecklingen av själva metakunskapen, hur vi kan utveckla arbetssätten i våra verksamheter för organisatoriskt lärande. Det som man kan göra med en gemensam rik informationsmodell. En sådan modell är mer än bara ER-diagram; den inkluderar ofta olika diagramtyper och även strukturerad text med tydliga definitioner och verksamhetsregler.
När jag idag informationsmodellerar tillsammans med systemutvecklare, blir de positiva och engagerade. De behöver och vill verkligen lyfta fram och arbeta kring verksamhetens domän tillsammans med verksamhetsexperter. Men de har sorgligt nog aldrig fått lära sig hur man gör det, utan har varit hänvisade till att själva försöka göra motsvarande direkt i programkod.
Resultatet är också att de som programmerar lever i en helt annan kunskapsvärld än de som modellerar verksamhet. Det är två yrkesgrupper som inte arbetar tillsammans och som läser olika böcker och artiklar. Vilket är synd, ty de har mycket att lära av varandra.
Jag har i artiklar lyft fram böcker som kommer från programmerarvärlden och som är högst intressanta för de som gör informationsmodeller, och tvärtom.
Renässans för informationsmodeller
Mot slutet av 00-talet började pendeln svänga tillbaka. Intresset för informationsmodellering började sakta växa. Visserligen från en låg nivå och sakta, mycket sakta. Men ändå stadigt. Det handlade till en del om att data kommit i rampljuset. Uppkopplade saker började leverera data i stora mängder. Man började tala om Big Data, det vill säga hantering av stora osorterade datamängder. Man pratade om en datadriven organisation, hur analyser av data skulle bli mer drivande för den operativa verksamheten. Lite senare började man anställa Chief Data Officers och informationsarkitekter. Just nu hajpar maskininlärning vars själva näring är data, högkvalitativa kuraterade data i stor mängd.
Så vintern är över, och en ny vår är här.
En ny hajp-cykel
Jag och mina kollegor har i flera år förberett oss för denna förväntade hajp kring allt som rör data. Vi har förstått att den skulle komma. Det är så klart bra att intresset är tillbaka. Men är det bara positivt? En hajp innebär att många kastar sig över något nyvaket och naivt och ser enkla lösningar. I vår bransch betyder det nästan alltid tekniska lösningar på problem som inte är tekniska. Vi har sett detta så många gånger. Leverantörer lovar enkla lösningar med sina verktyg eller metoder, när det som vi behöver är kunskap, erfarenhet, eftertanke och mognad.
Snart vänder så intresset, och vi halkar då brant ner i desillusionens dal. De enkla lösningarna fungerade inte, och intresset drar vidare till nästa hajp.
Hela detta mönster av på varandra följande hajper är i sig ett tecken på ett djupare problem vi har att tampas med, den bristande mognaden då det gäller verksamhets- och it-utveckling. Vi har en tendens att kasta oss över nya men enkla lösningar i hopp om att fixa allt åt oss.
Leverantörer profiterar på det, vilket är populism, enkla lösningar på djupare problem. När det visar sig inte funka är det redan glömt för då har nästa skinande nyhet dykt upp och drar till sig allt intresse.
Jag har hoppats att det i vår bransch skulle växa fram en mer sansad hållning, en mognad, att man inte ska falla i farstun. Men den mognaden verkar vänta på sig.
Efter hajp en följer backlash
Vi kan inte veta när vi når toppen på hajpkurvan, men vi kan vara säkra på att den kommer, och då vänder trenden snabbt och brant nedåt igen. Behovet av kompetens inom informationsmodellering är mycket stort inom nästan varje verksamhet, och det finns inte många som har den erfarenhet som krävs. Därför ser vi framför oss att fallet blir stort. I besvikelsen över att man inte kan få ordning på sin informationsresurs, trots nya verktyg och metoder avfärdar man kanske hela idén om att ta hand om data som en värdefull resurs. Kanske tror man då att AI kan göra jobbet. Den tanken har redan börjat dyka upp.
Vad kan vi göra?
Jag och mina kollegor vill möta och mota en sådan backlash, så gott vi kan. Vi tror att vi kan göra det genom att bidra till områdets utveckling. På riktigt, utan enkla och braskande lösningar. Vi har skapat en utbildning, ”Certifierad informationsarkitekt” som just nu går för andra året.
Vi har varit med och startat ett öppet nätverk: NIA, Nätverket för Informationsarkitektur i Sverige som snabbt fått 260 medlemmar. Det är viktigt att nätverket är öppet och fritt, vilket innebär att det inte är bundet till någon viss teknik, metod eller leverantör utan ägs och styrs av de yrkesverksamma själva. Ty det är när verksamma möts över gränser som utveckling sker.
Vi tror också på att skriva artiklar som belyser områdets olika aspekter, där du just nu läst den nittioförsta.
