Informationsmodellering för business intelligence

För oss informationsarkitekter är business intelligence en speciell värld, annorlunda mot resten av verksamheten. Där behöver man mer flexibla datastrukturer för att hantera strukturella förändringar över tid. Och det är ett sammanhang där vi har en viktig roll.
/Peter Tallungs, IRM, 2024-06-05
Business intelligence är speciellt
I den föregående artikeln skrev jag om likheten mellan den konceptuella och den fysiska informationsmodellen; att vi behöver strukturera data i en databas så att den stämmer väl överens med hur vi vill beskriva vad dessa data representerar i verksamheten. Det vill säga det som vanligen kallas för normaliserade data eller tredje normalformen (3NF).
Men den likheten gäller endast för de vanliga operativa/transaktionella it-systemen. Ty för business intelligence (BI) behöver vi fysiska datastrukturer som kraftigt avviker från den konceptuella modellen.
Varför är det så? Vad är det som gör BI så speciellt vad gäller datastrukturer? Det har att göra med den speciella typ av verksamhetsfunktion som BI är.
Två olika typer verksamhetsfunktioner
En verksamhet har två typer av verksamhetsfunktioner.
Operativa verksamhetsfunktioner
Här har vi alla de vanliga verksamhetsfunktionerna. De som gör det verksamheten är till för, som att producera varor eller tjänster samt hanterar alla de stödfunktioner som finns runt detta.
Analytiska verksamhetsfunktioner
En, ibland flera, verksamhetsfunktioner som har till uppgift att analysera och rapportera hur verksamheten fungerar. Det rör om regelmässig rapportering men också mer fritt undersökande för att hitta intressanta mönster i verksamhet och direkta omgivning. Mönster som kan tolkas för att berätta något och ge insikter. Detta kallas ofta för business intelligence (BI).
Trots samma data i botten har dessa funktioner mycket olika behov av dataanvändning och därmed behov av olika datastrukturer. De operativa funktionerna har en transaktionell hantering och därmed transaktionella it-system. Data avspeglar läget just nu och uppdateras kontinuerligt. Man skriver och läser en post åt gången. Data behöver vara aktuella och behöver vara normaliserade till tredje normalformen (3NF) för att undvika redundans.
Den analytiska datavärlden är helt annorlunda. Man laddar över data från de transaktionella systemen, vanligen vid midnatt varje dygn. De transaktionella systemen kallas i detta sammanhang för källsystem, eftersom de utgör källorna för data till data warehouse (DW). Sedan processas data i ett antal steg, konsolideras och presenteras på ett sätt som passar analys och rapportering. I dessa steg använder man sig av datastrukturer som inte följer tredje normalformen och därmed avviker kraftigt från både hur det ser i den gemensamma konceptuella modellen och i de fysiska modellerna i källsystemen.
Datalagring internt i data warehouse
BI-lösningens sekventiella processteg sker vanligen i en särskild it-miljö som kallas data warehouse (DW). DW är som en produktionsfabrik som hanterar uppgiften att transformera och hantera data från källsystemen så det passar behoven hos de analytiska användarna. Där behövs en datalagring som ställer speciella krav. Data behöver integreras från olika källsystem med olika strukturer.
Men vad som framför allt skiljer ut sig är att vi behöver lagra dessa data under mycket lång tid. Detta innebär att vi måste kunna hantera förändringar i datastrukturer över tid samtidigt som data måste vara jämförbara. Till exempel kan verksamheten omorganiseras så att försäljningen flyttas till andra organisationsenheter. Trots dessa förändringar vill vi kunna jämföra siffrorna efter omorganisationen med siffrorna före omorganisationen. Vi behöver kunna se försäljningssiffrorna både före och efter omorganisationen, fördelat på samma organisationsstruktur, vare sig det är den gamla eller den nya.
Därmed behöver man i DW en maximalt flexibel datastruktur. En struktur och hantering som tillåter förändringar i klassificeringssätt över tid med bevarad kontinuitet. Man delar upp varje entitet i delar som kan förändras var och en för sig. En tabell för själva företeelsens identitet och en tabell för varje attribut (eller logisk grupp av attribut), samt en tabell för varje relation företeelsen har till andra företeelser.
Det finns några olika metoder att välja på där man gör denna uppdelning. Vanliga metoder är Data Vault Modeling och Anchor Modeling. Båda har intressant nog anknytning till Sverige. Data Vault Modeling skapades ursprungligen av svensk-amerikanen Dan Lindstedt på 90-talet, och har utvecklats i nya versioner med svensken Hans Hultgren i ledande roll. Anchor Modeling har sitt ursprung i Sverige, och presenterades 2008 och utvecklas fortgående av ett team på Stockholms universitet med Lars Rönnbäck och Olle Regardt i spetsen.
Data Vault Modeling och Anchor Modeling har många likheter och ibland har man använt det gemensamma namnet Ensamble Modeling, då båda metoderna delar upp varje entitet i ett antal element som tillsammans bildar en helhet, en ensamble. Data Vault Modeling är den mest etablerade metoden av dessa två.
Data Vault Modeling
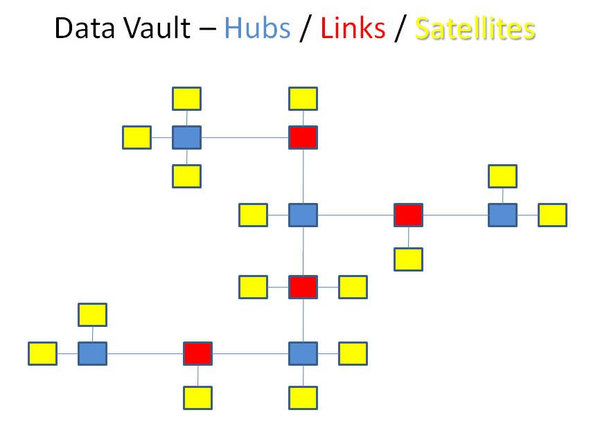
Data Vault Modeling fördelar attributen i en entitet från domänmodellen på flera tabeller. En Hub för själva identiteten hos entitetens förekomst. En Satellite för varje grupp av sammanhörande attribut, det vill säga attribut som ändras tillsammans, kommer från samma källsystem eller delar datatyp. Samt en Link för varje relation mellan entiteter.
Anchor Modeling
Anchor Modeling går ännu ett steg längre för att vara ännu mer flexibel, till priset av en ännu mer uppdelad struktur. Till exempel så har man strikt en tabell för varje attribut.
Observera att den fysiska datastrukturen i DW är inget som någon annan än DW-utvecklarna ser. Det är att betrakta som en teknisk lösning för att lagra data på ett sätt som fungerar över tid.
Presentation av data för BI-användare
Hur data sedan presenteras för BI-användarna är återigen en helt egen historia. Analytiker och rapportmakare behöver kunna ha tillgång till olika datamängder med en struktur som de lätt kan vända och vrida på, sortera, summera och filtrera utefter olika dimensioner. De behöver också kunna konsolidera och jämföra olika datamängder som då behöver dela gemensamt definierade dimensioner för att kunna sammanställas. Där fungerar varken tredje normalformen eller någon av de mera tekniska strukturerna som används internt i DW.
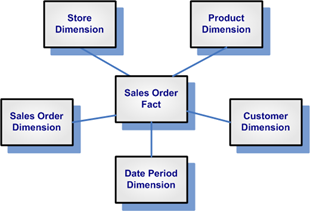
För att presentera data för BI-användare har man en typ av fysisk datastruktur som kallas dimensionsmodeller (Dimension Models) eller Star Schemas. Det är ett modellmönster och en metod som togs fram av amerikanen Ralph Kimball på 90-talet.
En stjärna har en faktatabell i mitten som typiskt representerar en händelse på lägsta nivå som har registrerats i en verksamhetsprocess. Sedan har den länkar till tabeller som representera olika dimensioner som används för att kategorisera denna händelse.
Dimensionerna är gemensamma. Samma dimensioner används i andra stjärnor. På så sätt kan man ställa frågor tvärs över flera stjärnor.
Det här är alltså, till skillnad från de föregående fysiska datastrukturerna Data Vault Modeling och Anchor Modeling, en fysisk datastruktur som är synlig för användare och till och med särskilt anpassad för användare.
Den gemensamma konceptuella modellen är central
Man har alltså behov av olika fysiska datastrukturer i BI-världen, som kraftigt avviker från en konceptuell vy av verksamhetens data (till skillnad från de fysiska datastrukturerna i den transaktionella världen). Men de betyder att man likafullt är beroende av en gemensam konceptuell informationsmodell, eller domänmodell om man så vill. Ty det är samma data i botten som representerar samma företeelser, med samma egenskaper. Så alla begrepp och benämningar behöver vara gemensamma. Det betyder att vi behöver ha en gemensam konceptuell modell som avbildar allt det som hanteras, tvärs över alla källsystemen, fast konsoliderat. Detta är oerhört viktigt. Vi behöver gemensam förståelse, gemensamma begrepp och termer, i hela verksamheten.
De fysiska modeller jag nämner ovan är bara olika fysiska strukturer för samma data och samma företeelser. När man utformar dessa behöver man utgå från domänmodellen. Modellen behöver vara detaljerad och rymma alla detaljer, både definitioner, benämningar, verksamhetregler, beskrivningar. Modellen blir det gemensamma språket och förståelsen. Inte bara internt för DW utan för begrepp och benämningar i all rapportering och analyser.
Vi informationsarkitekter behövs i den analytiska världen likaväl som i den operationella/transaktionella. Ja det är i praktiken till och med ett bättre och mer centralt område för oss än i verksamhetens operativa funktioner. I BI/DW-området har vi större möjlighet att skapa värde för hela verksamheten. Mer om detta i nästa artikel!
