Informationsmodellering: Hur vi kan namnge relationer
Jag vill ge ett alternativ till den vanliga principen för att namnge relationer mellan entiteter i informationsmodeller. Syftet är att namnen ska överensstämma med namnen för de verksamhetsbegrepp som relationerna representerar. Vi får därmed en spårbarhet från relationerna i våra informationsmodeller till termer i verksamheten och i informationssystemen.
Den vanliga principen för namngivning

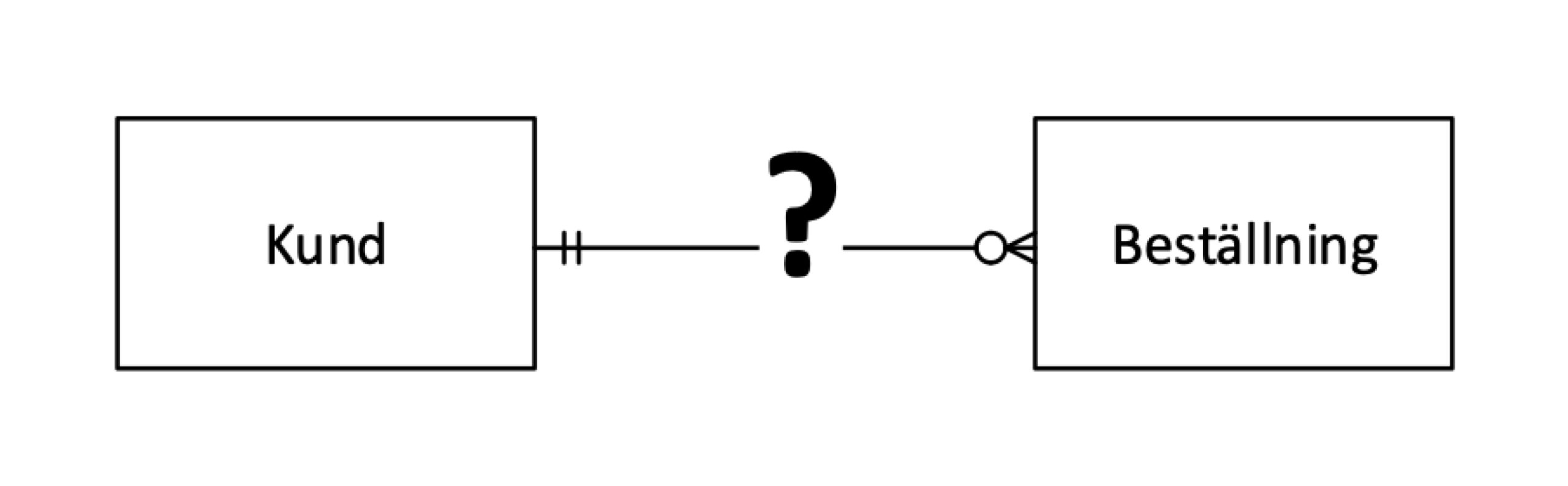
Det vanliga är att namnge relationer så att relationsnamnet tillsammans med entitetsnamnen blir mer eller mindre en verbal mening som går att uttala.
I exemplet till höger blir det ”Beställning läggs av Kund”. Det är tänkt att hela ER-diagrammet då blir läsbart som ett antal verbala uttryck. Det är en fördel, speciellt då det gäller ovana läsare av ER-diagram, och i varje fall då det gäller enklare diagram, det vill säga där man bara har ett antal entiteter och relationer och inga attribut.
Men jag menar att den principen för namngivning också har ett antal nackdelar, och att dessa tillsammans vida överskuggar fördelen. Jag beskriver problemen i det följande.
Problem 1: Namnen blir ofta intetsägande verb
Det blir ofta nästan omöjligt att undvika att relationsnamnen blir intetsägande verb som ”har”, ”tillhör”, ”är”. När vi talar så har dessa allmänna verb en funktion, men de kan aldrig fungera som verksamhetbegrepp. De beskriver inte vad relationen står för, i detta exempel vilken roll en kund har i en beställning. En relation har alltid en mening. De namn vi ger saker och ting bör uttrycka den meningen så klart och tydligt som möjligt.
Problem 2: Namnen uttrycker ofta handling
Om man vill undvika de mest allmänna verben, se ovan, så blir relationsnamnen ofta i stället verbsatser som uttrycker någon form av handling i tiden, som ”läggs av” i exemplet ovan. Problemet med sådana namn är just det att de uttrycker handling, det vill säga en process. Det fungerar inte så bra i en informationsmodell, som ju ska vara processneutral. Modellen ska bara uttrycka vilken information som kan finnas, inte hur den skapas.
Alla beställningar har en beställare, men så snart beställningarna finns så är beställningarna redan lagda. ”Läggs av” är historia, det var något som skedde någon gång, i det ögonblick beställningen gjordes. Det gör att informationsmodellen får drag av process, vilket är falskt. ”Lagd av” vore mer korrekt i så fall, men är ändå inte bra, eftersom det mer talar om hur relationen skapades än vad den innebär.
Problem 3: Namnen blir inte verksamhetstermer som kan användas i andra sammanhang.
Den kund som lagt en beställning är ”Beställare” på beställningen. Det är en egenskap hos en beställning. En relation är således alltid en egenskap hos en entitet samt också ett verksamhetsbegrepp som bör definieras, beskrivas och normeras. Det är det vi har informationsmodellens textdel till. Och där kan egenskapen inte heta ”Läggs av” eller ”Har”. Knappast heller ”Kund” eftersom det namnet bara uttrycker vilken klass av objekt som utgör värdeförråd för egenskapen, och inte vad relationen har för mening.
Sedan ska relationen realiseras i olika sammanhang. Den kanske blir en; databaskolumn, variabel i programkod, fält i en fildeklaration, ruta i användargränssnitt eller term i en rapport? Då, om inte tidigare, behöver vi ett tydligt namngivet, definierat och normerat verksamhetsbegrepp. Detta är enligt min mening informationsmodellens jobb. Precis som vi gör med entiteter och attribut. Då fungerar termen ”beställare”, men knappast de intetsägande namnen man ofta ser i informationsmodeller.
Vad vi vill med namngivning
Vi kan tänka efter vad vi egentligen vill med namnen, vad som är ett bra namn. Ett namn ska förstås vara så korrekt och tydligt som möjligt men också så användbart som möjligt. Det innebär att det ska fungera i så många olika sammanhang som möjligt, det vill säga alla de sammanhang som informationsmodellen kan komma att användas i. Man brukar ibland uttrycka det som att informationsmodellen ska vara process-agnostisk, det vill säga inte ha något spår av hur företeelserna kommer till eller hanteras, bara att de finns och vad de har för mening.
Jag tycker att det är viktigt att våra modeller, blir användbara som underlag för implementationer av informationssystem av olika slag. Det kan vara databaser, programkod, filer, meddelandescheman, användargränssnitt, api:er, rapporter med mera. Vi normerar ett språk för allt det som hanteras och presenteras. Då gäller det att de namn vi väljer blir så användbara som möjligt. Men då måste vi ha en namngivning som är så pass användbar att den verkligen fungerar i skilda sammanhang.
Men jag vet att det finns en mer traditionell uppfattning som säger att det inte är något värde att försöka tillämpa samma namngivning i informationsmodeller som i fysiska sammanhang. Man ser det som olika världar som ska hållas isär. Vi gör konceptuella modeller och bryr oss inte alls om det ”tekniska”, säger man. Man är alltså inte bekymrad för om informationsmodellen säger något om den fysiska verkligheten, eller ens om den är användbar i praktiska sammanhang.
Jag är av motsatt åsikt. Jag menar att vi så lång det går bör jobba ihop, tvärs över alla roller i organisationen och så långt det går ha gemensamma modeller. Det är ju det modeller är till för, att ge oss en gemensam bild, en gemensam förståelse att jobba med och att utveckla tillsammans.
Nyckeln är ”så långt det går”. Det kommer alltid att finnas skillnader mellan modeller och det modellerna används till, men låt oss sträva efter att hålla dessa så små som möjligt. Detta är en princip som kommer från den filosofi som heter ”domändriven design”, och som jag tycker är helt avgörande för vilken nytta våra modeller ska kunna ge. Jag har skrivit om detta synsätt i många tidigare artiklar.
Mitt förslag till namngivningsprincip
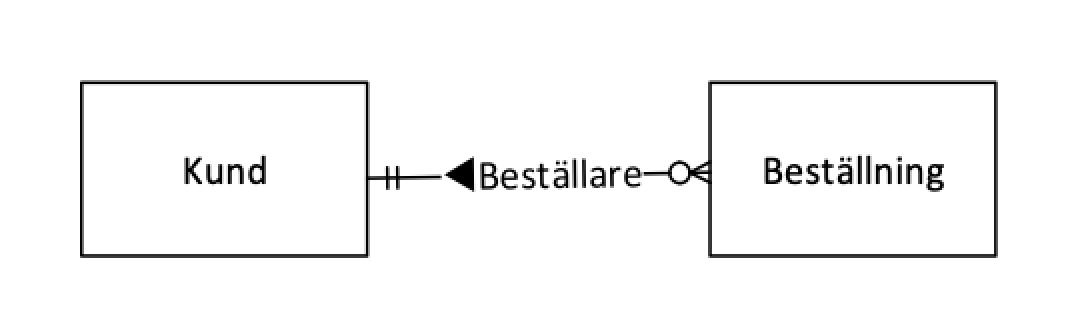
Mitt förslag är en namngivning som jag tillämpat i ett par decennier och som jag tycker fungerar bra.
En relation är egentligen inget annat än en egenskap hos en entitet. Närmare bestämt en egenskap som innebär att entiteten har en relation till en annan entitet. Man kan också uttrycka det som att egenskapen har ett värdeförråd (en värdedomän) som definieras av den andra entiteten, det vill säga den klass av företeelser som den andra entiteten representerar. I exemplet, som är genomgående i denna artikel, är det Beställning som har egenskapen ”Beställare”, som enligt ER-diagrammet är en obligatorisk egenskap och som har ett värdeförråd (möjliga värden) som är mängden av alla kunder.
Allt det vi behöver definiera och beskriva för övriga attribut behöver vi också beskriva för de attribut som manifesterar relationer, såsom namn, synonymer, beskrivningar, värdeförråd, format och regler. Varför ska vi då behandla relationer på andra sätt än andra attribut?
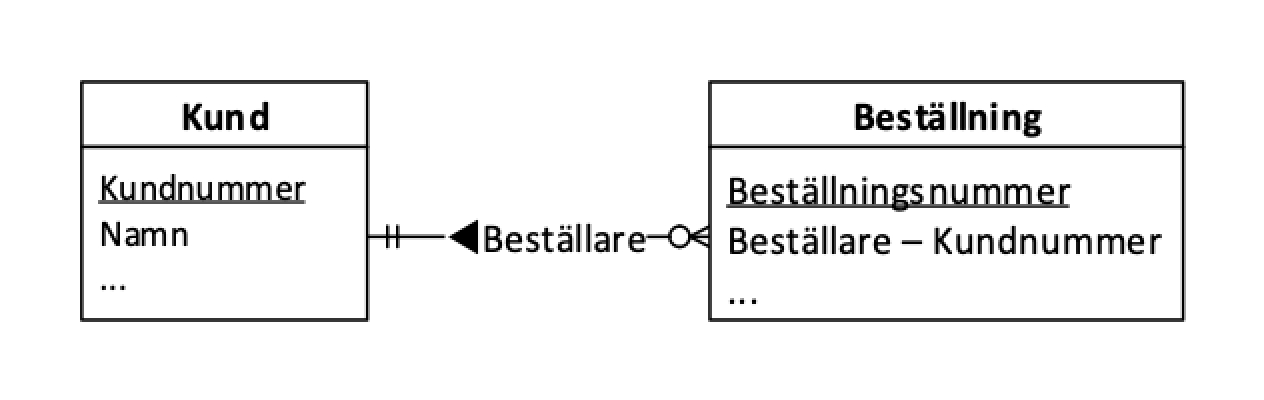
Låt oss se hur det blir när vi beskriver detta med hjälp av attribut.
Namnet på attributet skulle jag skriva ”Beställare – Kundnummer”. Ofta blir namnet lite mer specifikt än vad relationen heter. Vi vill ju kunna säga att i detta fall är det beställarens kundnummer som är egenskapen.
En del kanske tycker att man kan utelämna suffixet ”Kundnummer”. En främmande nyckel ska ju ändå alltid peka på primärnyckeln i den entitet den pekar på. Men jag föredrar att ha med det ändå. Man kan inte vara nog tydlig. Det kan ju också finnas till exempel ”Beställare – Namn”.
Nu har vi fått en tydlig spårbarhet mellan diagram och de attribut man beskriver i textdelen av modellen.
Det finns de som reagerar på det osköna i redundansen i detta sätt att göra, det vill säga att samma sak beskrivs två gånger, en gång som relation och en gång som attribut. Att en beställning har en kund som beställare beskrivs både med relationslinjen och med attributet. Man kan då undra om det är samma sak eller inte. Jag förstår invändningen, men menar att den väger lätt. Jag tycker att det är ett pris värt att betala, bara man är tydlig med namngivning och beskrivning.
Namngivning enligt databasstandard
Det finns en annan princip för namngivning av attribut som manifesterar relationer som man ofta stöter på och därför är värd att nämna. Det är det namnskicket som är vanligt i databassammanhang. I en traditionell databas är ju en relation manifesterad som en databaskolumn, vilken är en främmande nyckel, det vill säga den innehåller värden som återfinns som primärnyckel i en annan tabell. Då brukar man ge den kolumnen samma namn som den tabell och kolumn den pekar på. I exemplet ovan skulle då attributet heta Kund.Kundnummer. Fördelen för databasdesigners är att detta namnskick underlättar så att man automatiskt kan hantera relationer. Fast jag tycker att det namnskicket inte passar för en bredare användning. Man säger visserligen att kolumnen innehåller ett kundnummer men det viktigaste tycker jag ändå är att uttrycka relationens mening.
Relationers riktning
Inom traditionell data- och informationsmodellering har relationer inte någon riktning. Det beror på att informationsmodellering har ett ursprung i relationsdatabasdesign. I en relationsdatabas kan en relation traverseras i vilken riktning som helst, till exempel med frågespråket SQL. Däremot så har relationsnamnet alltid en viss läsriktning, det vill säga namnet är tänkt att läsas från en bestämd entitet till den andra. Man kan dock lika gärna behöva sätta ett namn med motsatt läsriktning. Eller ha två namn, ett åt vartdera hållet. Det finns de som förespråkar det.
Men så fungerar inte alla modelleringsspråk. I klassmodeller i UML är det annorlunda, därför att UML ursprungligen är framtaget för att strukturera objektorienterad programkod. Där har relationer alltid en bestämd riktning. Om man i programkod vill kunna traversera i båda riktningarna behöver vi skapa två relationer, en för vardera riktningen.
I programkod, liksom i olika språk för datascheman, är det dessutom vanligt att relationer går åt hållet från en till många. I programkod skulle förmodligen en kund ha en kollektion av pekare till de beställningar kunden är beställare på.
Allt detta gör att det är viktigt att vi pekar ut riktningen för våra relationer, vare sig det rör sig om att relationen verkligen har en bestämd riktning eller det handlar om läsriktning för det namn vi väljer att ge den. Jag gör det med en liten fylld pilspets som i exemplet.
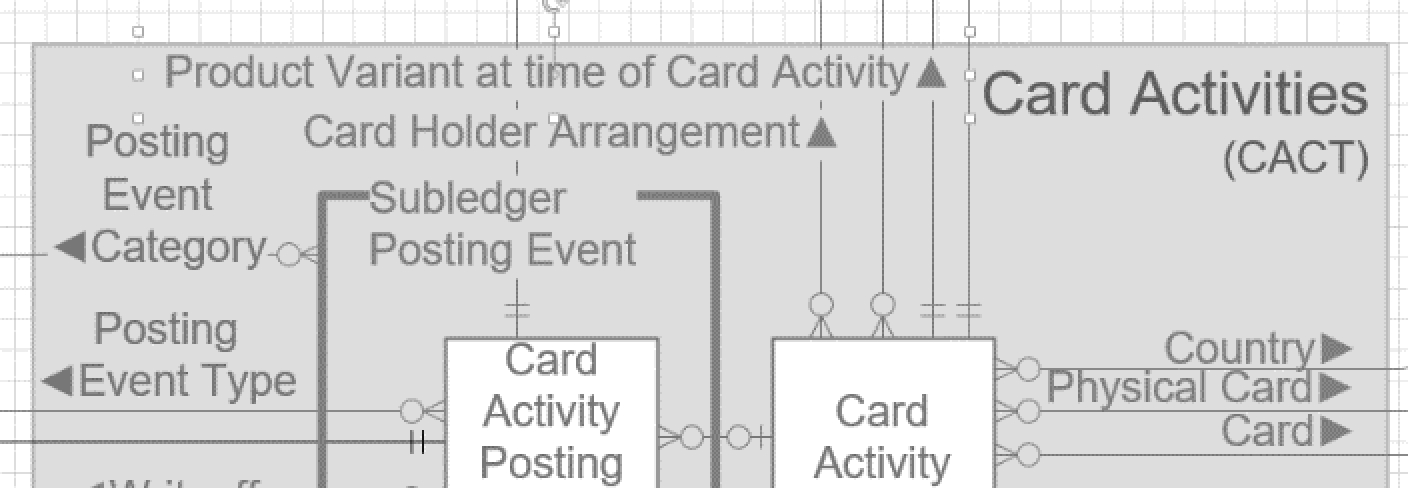
En annan fördel med en sådan pilspets vid relationsnamnet ges exempel på här till höger. Ibland har man många relationslinjer som går ut vertikalt från en entitet. Då kan en sådan pilspets tydligt markera vilket namn som hör till viken relationslinje. Se de relationer som går vertikalt uppåt från entiteten ”Card Activity”.
Låt oss diskutera och utveckla vårt område!
Allt detta är förstås bara mina egna erfarenheter och åsikter, inte en slutgiltig ”sanning”. Men det är något vi borde diskutera och utveckla. Jag har saknat en sådan dialog. Det är därför jag skriver dessa artiklar.
