Så kartlägger du verksamhetens dataflöden
Som informationsarkitekt behöver du kartlägga var data kommer från, tar vägen, transformeras och används. Så här gör du.
/Peter Tallungs, IRM, 2025-05-08
Var kommer våra data från – och vad händer med dem?
Om vi ska få koll på verksamhetens data räcker det inte med att kartlägga vilka data vi har och vad de betyder, det vill säga det vi gör med informationsmodellering och dataprofilering. Vi behöver också få koll på var de olika datamängderna kommer från och tar vägen, samt var, av vem, hur och varför dessa datamängder hanteras, transformeras och används.
Det vedertagna namnet för detta perspektiv på datahantering är data lineage. Den engelska termen lineage översätts med härstamning. Jag tycker dock att den termen inte riktigt förmedlar hela det perspektiv som omfattas av begreppet. En definition som förekommer är ”Data lineage is the process of tracking the flow of data over time, providing a clear understanding of where the data originated, how it has changed, and its ultimate destination within the data pipeline”.
Jag har ibland kallat det för dataflöde, men det känns kanske också lite för svagt. Det handlar ju inte bara om ett passivt flöde utan om allt som händer på vägen från källa till konsument. Ibland säger jag hellre datalogistik. Logistik definieras som: ”Planering, implementering, styrning och kontroll av effektivitet i materialflöde och tillhörande administrativt flöde, från materialförsörjning till leverans till kunderna.”
Och det är väl det vi är ute efter; om vi byter termen ”material” mot ”data”.
Nåväl. Vi kan kalla det data lineage, dataflöde eller datalogistik, bara vi menar samma sak.
Man kan säga att våra informationsmodeller tillsammans med dataprofilering ger det statiska perspektivet på våra data (vilka data som finns), medan datalogistiken tillför ett dynamiskt perspektiv (vad som händer med dessa data).
Varför behöver vi ha koll på våra dataflöden?
Varför är det viktig att vi har koll på dataflödet för våra olika datamängder?
Svaret är i breda drag följande. Det är en grund för att vi ska kunna se till att försörjnings- (och konsument-) kedjan för data är:
- känd
- robust och pålitlig
- resilient (det vill säga kan stå emot, klara av och återhämta sig vid störning och annan påverkan)
- utvecklingsbar.
Vi behöver känna till hela kedjan, från början till slut. Ty det vi inte vet om och i detalj förstår kan vi inte förbättra. Alla former av underhålls- och förbättringsarbete (vad det än gäller) måste börja med att vi faktiskt kartlägger vad som finns och hur det hänger ihop. Det är här datalogistiken kommer in.
Ett och samma flöde
Inom it- och verksamhetsutveckling har vi en seglivad vana att se it som något separat och avgränsat från verksamhet – trots att man ofta ivrigt hävdar det motsatta! Följaktligen är det vanliga att man delar upp data lineage i två separata spår:
- Technical data lineage – som beskriver hur data rör sig mellan it-system och deras integrationer.
- Business data lineage – som beskriver data flödar genom parter, verksamhetsfunktioner och roller i verksamhetens inre och yttre ekosystem.
Så länge vi envisas med att kartlägga verksamhet och it var för sig kommer detta att fortsätta.
Vi behöver se det annorlunda. Jag och mina kollegor betraktar dataflödet som ett och samma flöde. Verksamhetskartan är själva förutsättningen för att hålla ihop det, eftersom den visar it och verksamhet som en integrerad helhet, som ett och samma landskap.
Det är avgörande att verksamhets- och it-folk kan samlas kring gemensamma modeller. Varför skulle vi med vett och vilja fortsätta att befrämja den kommunikativa friktion det för med sig att olika delar av organisationen har olika bilder i huvudet av samma verklighet? Alla riktigt intressanta modeller samlar flera perspektiv.
Vad ska vi använda kunskapen till?
Om vi ska bli lite mer konkreta: Vad ska vi ha kartlagda dataflöden till? Vilka frågor i verksamheten kan det hjälpa oss att hantera?
Här är några exempel:
Felsökning
Om verksamheten är beroende av data för beslut, men misstänker fel i dessa data, kan dataflödet i verksamhetskartan hjälpa oss spåra flödet bakåt för att hitta rotorsaken.
Påverkansanalys
När vi vet att en datakälla kommer att förändras kan vi följa flödet framåt i kedjan. Då vet vi vad och vilka som påverkas, vad vi behöver förbereda och vem vi behöver förvarna.
Källanalys vid behov av nya data
När våra analytiker behöver nya data kan de med hjälp av kartan identifiera möjliga dataägare och datakällor för att därifrån sätta igång processen att få tillgång till relevanta data.
Tilltro till data
När dataanalytiker kan se proveniensen – varifrån data kommer, hur de färdas och vad som hänt längs vägen – växer tilliten till de data de använder. Eller motsatt: En misstro, då denna är berättigad! Trovärdigheten hos data beror på källan och vem som förmedlar.
Kartlägga personuppgifter
Kartan hjälper oss att följa hur persondata sprids och lagras i verksamheten och it-landskapet. Det är avgörande för att till exempel säkerställa radering av persondata enligt GDPR-kraven.
Beredskapsplan för dataförsörjning
En beredskapsplan ska hantera den kritiska dataförsörjningen. För att ta fram en sådan behöver vi följa flödet bakåt i kedjan, detta för att kunna planera motverkan av hot mot datakällor och dataflöden.
Optimering av dataförsörjning
Det händer att man har flera standardsystem som vart och ett integrerar mot olika externa datakällor, och att de data man då betalar för överlappar, helt eller delvis. Vi behöver identifiera och hantera överlappande data samt reducera eventuell onödig redundans.
Arbete med användbarhet och datakvalitet
För att förbättra vilka data och dataflödena vi har behöver vi förstå hur data används. Vi behöver identifiera, söka upp och samverka med de som hanterar och använder våra data, inte bara slutanvändare, utan också utvecklare, rapportbyggare med flera. De sitter ofta långt nedströms i kedjan och ibland utanför den egna organisationen. Vi behöver intervjua och undersöka: Vad fungerar, vad kan bli bättre? Vilka nya behov ser de framöver? Vi behöver bygga ett löpande samarbete med dessa intressenter. Verksamhetskartan ger med sina kartlagda dataflöden den översikten vi behöver för att orientera oss i det landskapet.
Bygga upp data management-förmågan
För att bygga data management-förmågan krävs mer än ett centralt team. Vi behöver roller ute i verksamhetens olika delar, hos de som använder, skapar och påverkar data. För att bygga och hantera den organisationen behöver vi veta vem som använder vad, hur och varför.
Dataflöden är inte linjära
Ett dataflöde är inte som ett rakt rör. Det är sällan så enkelt att en viss datamängd skapas på ett ställe och sedan följer en rak väg tills den används. Flödet liknar snarare ett träd, med både spretande rötter och grenar, där vi i data management-teamet sitter i stammen.
Och vi har sällan att göra med enkla, enhetliga ”dataprodukter”. En datamängd kan vara sammansatt eller härledd från flera andra datamängder. Den kan bestå av poster som härrör från olika källor. Eller så kan varje enskild datapost vara sammansatt av, eller beräknad utifrån, olika termer som i sin tur kommer från olika håll, både inom och utanför organisationen.
De källor vi ser är dessutom sällan de ursprungliga. De vi har kontakt med har ofta egna källor, som vi kan behöva spåra vidare bakåt.
En viss datamängd sprids ofta åt olika håll, till olika parter, liksom till olika användningsområden, både inom och utom organisationen. På vägen transformeras data på olika sätt, byter format och termnamn. Namnbyten kan vara relevanta på grund av att ändrat kontext, men ofta är de bara slarvigt satta och missvisande begrepp, vilket skapar förvirring och ibland grova fel i analyser och rapporter.
Dataflöden är okända
Allt detta som händer med våra data är nästan alltid odokumenterat och föga förstått i våra verksamheter.
Ansvaret hamnar mellan stolarna. It-gänget säger att det är verksamhetens data. Deras ansvar är att se till att rören fungerar, inte vad som ska flöda däri. Verksamhetsfolket i sin tur har varken verktyg eller kunskap att ta kontrollen. De kan inte överblicka eller undersöka vad som sker i eko-systemet av databaser, integrationer, filer och programkod.
Det är här som vi informationsarkitekter har vår roll. För varje dataområde behöver vi kartlägga hela flödet – vad som händer i varje punkt, varför det händer och vem som har ansvar. Och göra detta till gemensam kunskap. Samt inte minst bygga organisation, kunskap, kultur och arbetssätt för att kontinuerligt ta ansvar.
Verksamhetskartans roll
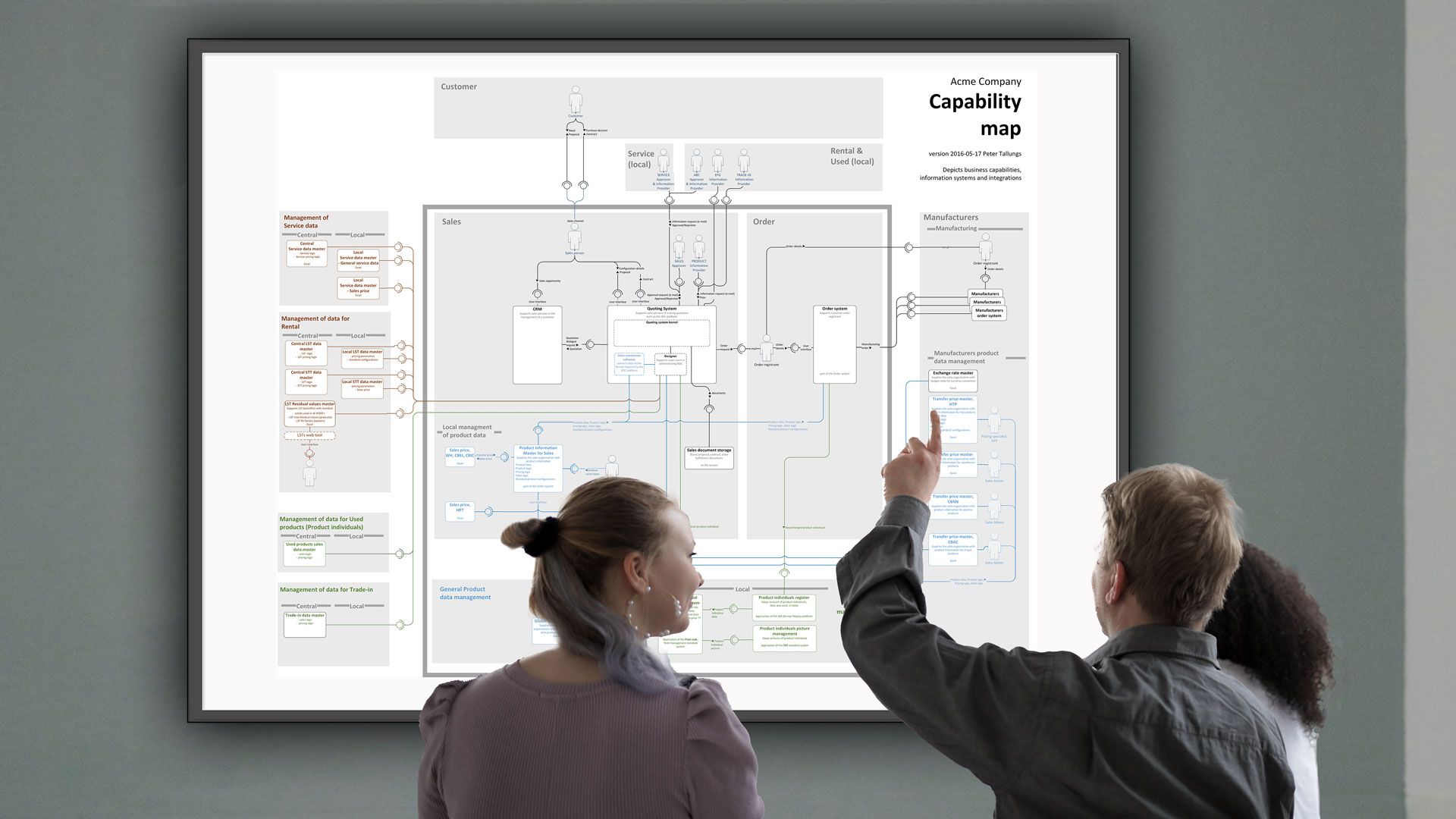
Jag och mina kollegor använder, som tidigare nämnts, verksamhetskartan som grund för detta arbete. För att kunna beskriva flödet behöver vi först kunna visualisera det landskap flödet rör sig genom, det vill säga verksamhetens landskap där och it-systemen och integrationerna finns som integrerade delar.
Verksamhetslandskapet består av externa och interna parter (verksamhetsfunktioner med sina it-applikationer och personroller). Parterna samverkar på olika sätt, både manuellt och automatiserat. Och all den samverkan sker genom tjänster, det vill säga att en part erbjuder någon form av nytta till en eller flera andra. Alla regelmässiga data- och informationsflöden inom och mellan verksamheter sker just i användning av tjänster. Tjänster som vi kan kartlägga och visa i verksamhetskartan.
Så här kartlägger vi
Men hur gör man rent praktiskt? Så här brukar vi gå till väga.
Vi börjar med att välja ut ett dataområde att kartlägga, dokumentera och visualisera flödet för. Vanligtvis sker detta som en del av det större arbetet med att bygga upp data management, enligt det som beskrivs i artikeln 12 steg för att bygga data management – Steg 6: Kartlägg logistiken för kunddata.
Vi använder kunddata som exempel här, men arbetssättet gäller i princip alla data – särskilt masterdata. All annan data än masterdata är oftast enklare att få bukt med.
Utgångspunkten är att vi har en första version av en informationsmodell för kunddata. Den ska helst vara så detaljerad som möjligt, med grafiska beskrivningar, ER-diagram kompletterat med tillståndsdiagram (state charts) och förekomstdiagram (instance diagrams) där det behövs, samt alltid med strukturerad text med namn, synonymer, definitioner, beskrivningar med mera. Det vi brukar kalla en ”rik informationsmodell”.
Vi brukar utgå från en i verksamheten central databas för kunddata. Vi tolkar strukturen och beskriver både den konceptuella och fysiska strukturen i samma modell, för att få översikt och samband. (Ett vanligt missförstånd är att man måste separera perspektiv. I själva verket är det tvärtom, att intressanta modeller kombinerar perspektiv i samma vy.)
Så här kan den arbetsgången se ut:
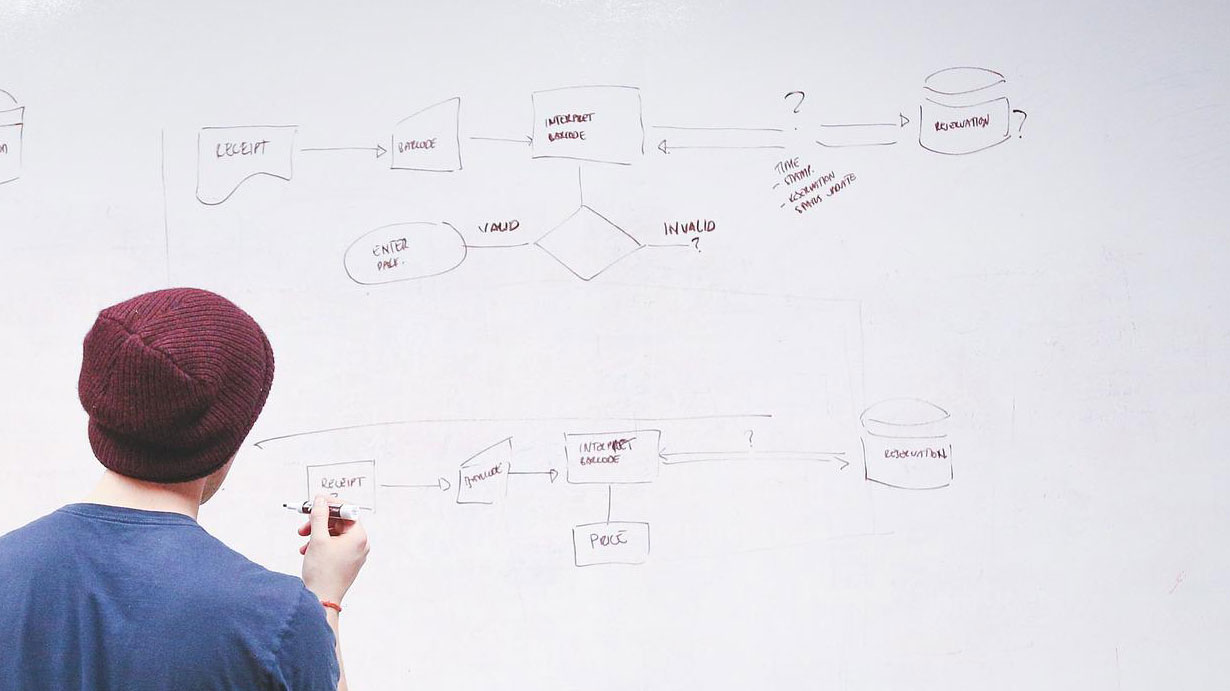
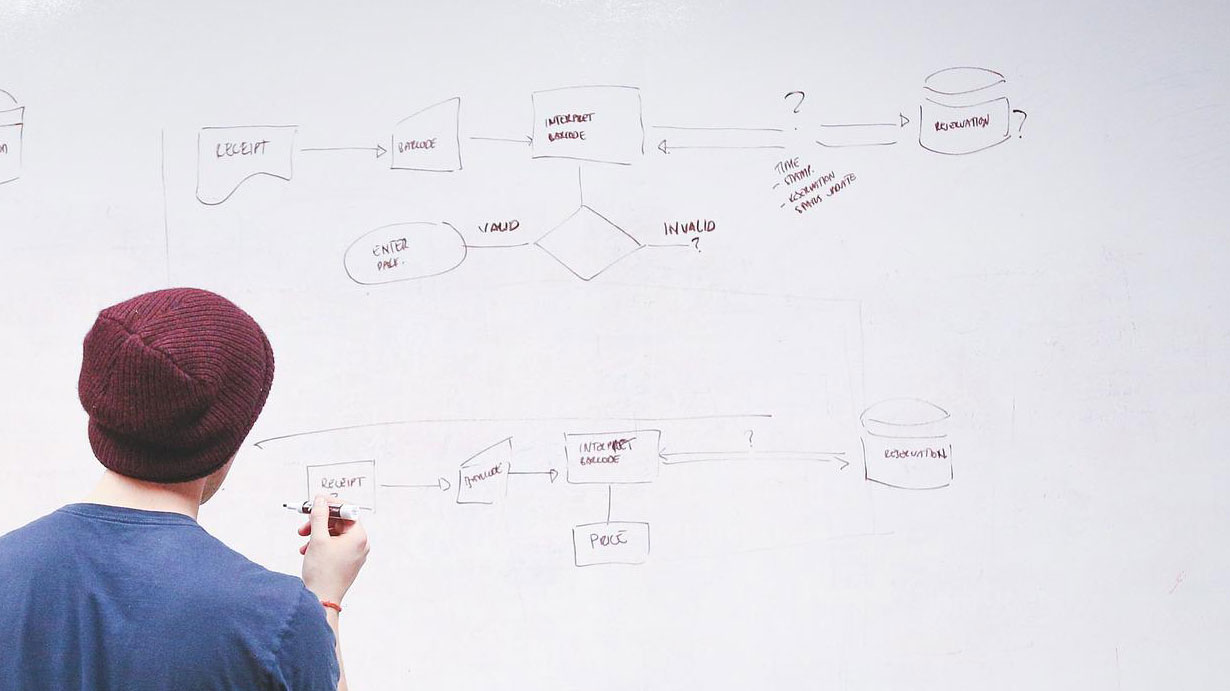
Kartlägg bakåt: Spåra ursprung
Var kommer varje term ifrån? Hur är dess historia?
Vissa termer har internt ursprung. Kanske är det Sälj eller Marknad som lägger upp en ny kund, sätter kundstatus etcetera. Men ofta hämtas också uppgifter externt om organisationer eller individer som är kunder. De företag som tillhandahåller dessa uppgifter hämtar i sin tur dessa från olika myndigheter som Skatteverket, Bolagsverket, Statistiska Centralbyrån med flera.
Vår uppgift blir att kartlägga hur dessa datatermer är strukturerade och namngivna, var de kommer från, samt vad de egentligen betyder – vilket sällan är självklart. Ofta saknas tillförlitlig dokumentation, även hos företag vars hela affärsidé är att sälja data.
Frågor vi behöver svar på:
- Hur ofta kommer nya dataleveranser?
- Hur aktuell är den data som levereras?
- Vad säger leveranskontrakt (både i vad som är skrivet och vad som är underförstått)?
- Hur, var och av vem hanteras dataleveranser, både hos leverantören och hos oss?
- Vilka är kontaktuppgifterna till dessa?
De flesta organisationer tar regelbundet in data om kunder och andra intressenter från externa leverantörer. Det är inte ovanligt att man spar dessa filer, men att man sedan av olika skäl inte tar allt innehåll vidare till sin kunddatabas. Det har hänt att jag hittat sådan ”skuggdata”, som man betalar för och har ansvar för men som varken verksamhet eller it känner till.
Mitt första jobb som informationsarkitekt brukar bli att nysta upp och dokumentera hela flödet bakåt – som en detektiv med informationsmodell och verksamhetskarta som verktyg.
Min erfarenhet är att de företag som säljer data ofta har dålig koll på vad de faktiskt levererar. De har ofta minst lika stor nytta av kartläggningen som vi konsumenter. Bristen på informationsarkitektur och data management är inte endast ett lokalt problem, den är epidemiskt spridd i hela samhället. I tre decennier har it setts som en teknisk fråga, inte som informationshantering. Detta är något som hämmat våra verksamheters utveckling och fortsätter att hämma, så länge som vi inte börjar ta ansvar.
Kartlägg framåt: Spåra spridning och användning
Nu när vi fått grepp om vilka data vi har, varifrån de kommer och vad som hänt längs vägen, behöver vi förstå hur dessa data sprids och används, internt och ofta också externt.
Vi börjar med att kartlägga vilka integrationer som finns med den centrala databasen för kunddata. Det kan vara api:er, filöverföringar, genererade standardrapporter eller användargränssnitt för sökning direkt i databasen.
Allt detta behöver vi undersöka och dokumentera. Ofta finns det många versioner av samma api, inklusive gamla versioner som fortfarande används, men vars användning inte är känd och dokumenterad.
På så sätt får vi fram vilka parter (verksamhetsfunktioner med sina applikationer och roller) som direkt använder dessa data. Nästa steg bli att söka upp representanter för parterna och undersöka vad de använder och till vad.
Vanligen refereras och integreras kunddata med andra data, så som beställningar, offerter, ordrar, rapporter etcetera. Vi behöver följa kunddata vidare genom dessa steg, och förstå hur användningen förändras längs vägen.
När dataflödet är känt och dokumenterat i verksamhetskartan och när vi har byggt samverkan med alla intressenter på vägen har vi förutsättning för steg för steg förbättra och förstärka dataförsörjning och dataanvändning.
Hur det ser ut i våra organisationer
Hur ser det då ut i våra företag och myndigheter. Vad gör man? Tja, det finns mycket att göra.
Det slår mig ofta hur man genom åren integrerat data från olika håll, så att man idag har en enda stor soppa. Ingen i organisationen har koll. Man behöver då ta ett tydligt grepp och ansvar, på detta sätt vi talar om här.
Utveckla i små steg
Många gånger vill man bygga en ny systemlösning för att ersätta en oordning, ofta baserat på något standardsystem. Det kan kännas som en vettig väg att ta ett rejält grepp och städa bort allt gammalt. Men det är aldrig lösningen! Tvärtom brukar detta förvärra läget. Om man alls lyckas leverera, det vill säga utan att man vet vad man har för data och vad de används till. Man försöker ersätta något man inte förstår. Ty man kan inte ersätta det man inte i grunden känner till vad det gör.
Om man i stället, på det sätt jag beskrivit ovan, först skaffar sig kunskap (vilket vi egentligen kan göra ganska enkelt) så blir lösningen nästan aldrig att skrota allt gammalt i en big bang. Den framkomliga vägen är att i små, kontrollerade steg, stärka hela kedjan en bit i taget. Det kan ju innebära att vi byter system eller systemkomponenter någonstans, men det är inte alltid hela lösningen, och heller aldrig någonsin själva kärnan i lösningen.
Ty oredan har aldrig tekniska orsaker, och därmed heller inga tekniska lösningar. Lösningen är alltid att bygga egen gemensam kunskap, ansvar och kontroll.
Det är bara systemleverantörer som vill få oss att tro att en ny systemlösning är det vi behöver. De har en tacksam marknad hos interna intressenter som är sugna på stora, karriärdrivande statusprojekt. Och de finns både på verksamhets- och it-sidan.
Det vi inte förstår kan vi inte avveckla
Ofta har jag också mött inställningen ”Vi behöver inte dokumentera det gamla – det ska vi ju ändå skrota snart.” Men den tanken bygger på en bristande förståelse om kunskapens roll i förändringsarbetet. För att ersätta ett system måste vi först förstå exakt vad det gör, och för vem.
Denna oförståelse är vanlig och har gjort att vi idag i våra organisationer ofta har flera olika system för samma sak. Man har försökt ersätta ett äldre system, men på vägen inte riktigt lyckats avveckla det gamla, utan lever vidare med både det gamla och nya parallellt. Resultat: Ökad komplexitet.
Detta är inget olyckligt undantag. Det är normen. Det är svårt att hitta exempel på lyckade systeminföranden.
Hur gör ni?
Hur arbetar ni i er organisation för att få grepp på datalogistiken?
Vilken erfarenhet har du?