Vilka datadomäner ska vi ha?
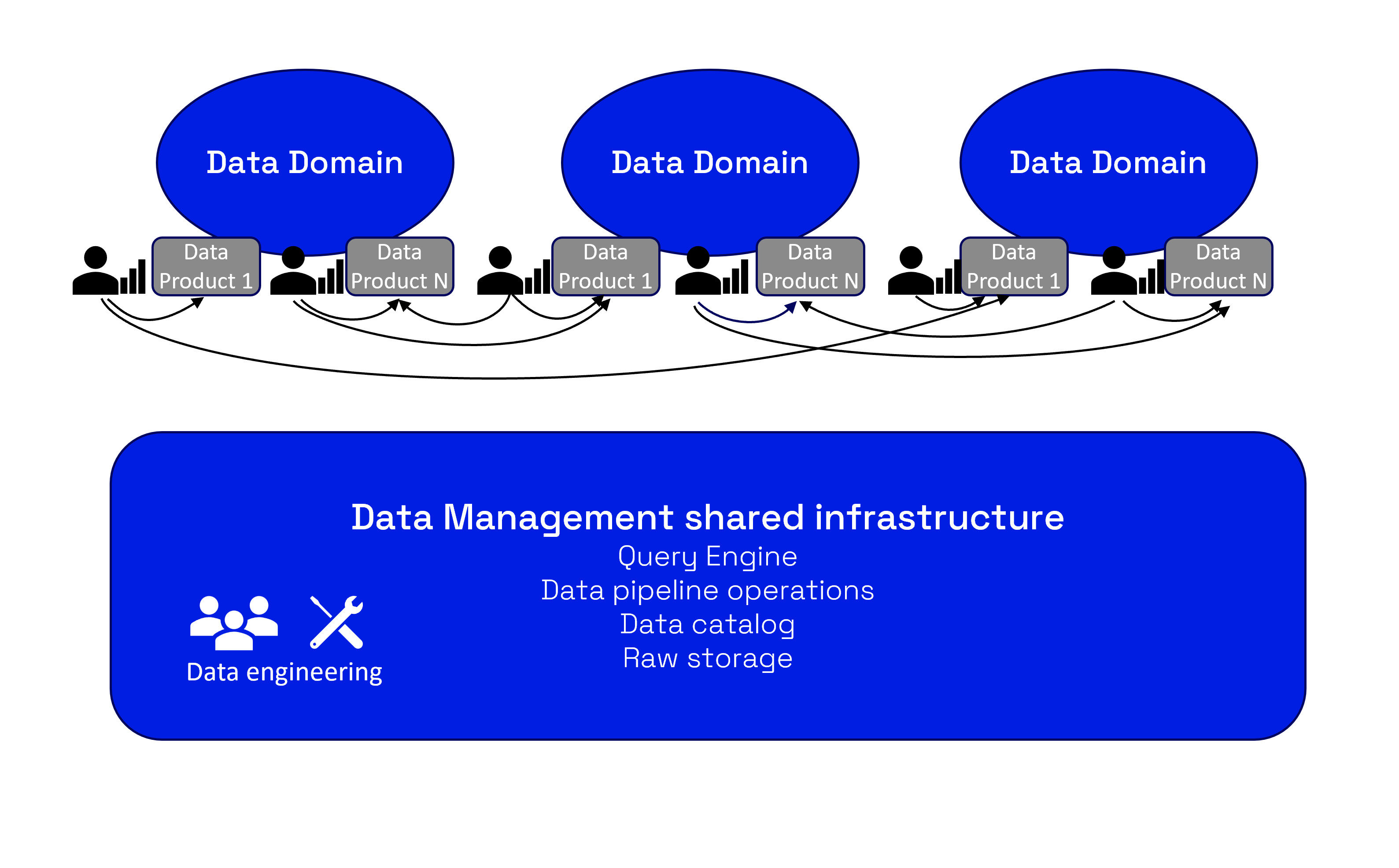
Om vi ska bygga upp Data Management i våra organisationer behöver vi stycka elefanten. Vi behöver dela in vår verksamhets data-/informationsresurs i domäner. Hur gör vi lämpligen detta?
/Peter Tallungs, IRM 2023-11-30
Vad är datadomäner och vad ska vi ha dem till?
Våra organisationer behöver hantera stora mängder data av många slag. Vi behöver då på något sätt dela in organisationens hela dataresurs i avgränsade områden för att fördela prioritet, ansvar och arbete.
Det är vanligt att kalla dessa områden för data- eller informationsdomäner. Domän betyder helt enkelt område. Det är en allmän term som har olika betydelser i olika sammanhang. När vi pratar om data- eller informationsdomän menar vi ett lite större område av hela vår data-/informationsresurs som vi vill se och hantera som en egen helhet. Men vilken indelningsgrund ska vi använda, hur ska vi tänka då vi bestämmer vilka datadomäner vi ska ha? (Jag skriver här för enkelhetens skull datadomän.)
Vilka aspekter av datahanteringen ska omfattas?
Vi bör först gå lite djupare i frågan om exakt vad som ska hanteras. Min erfarenhet är att man ofta inte klargjort vilka aspekter av datahanteringen som ska omfattas. Utan undantag blir det då att vi pratar förbi varandra eller helt ignorerar någon aspekt. Därför bör vi först fråga oss: Vilka aspekter omfattas? Om jag är ansvarig för en domän, exakt vad är jag ansvarig för? Det räcker inte med att svara ”allt”. Vi behöver reflektera över vilka aspekter som finns och vad varje aspekt egentligen innebär.
Här följer exempel på aspekter av datahantering som man kan diskutera och som alla bör hanteras på något sätt i våra verksamheter:
Fysisk datahantering
Planera och etablera lagringskapacitet, teknik för integration och säkerhet etcetera.
Datakvalitet
Monitorera, analysera och beskriv fel och brister i befintliga data. Jämför med intressenternas behov. Åtgärda felen och bristerna, och etablera hantering för att bristerna inte ska återkomma.
Data-/informationssäkerhet
Analysera, beskriv och hantera krav på auktorisation, autenticitet och beständighet.
Informationsarkitektur
Analysera och samordna hanteringen av data och information genom att ta fram, underhålla och använda modeller och beskrivningar av olika slag.
Informationsarkitekturen kan i sin tur omfatta följande aspekter:
- Data- och informationsstrukturer, fysiska och logisk
Med hjälp av data- och informationsmodeller (eller gärna rika informationsmodeller som integrerar fysiska och logiska aspekter).
- Dataterminologi
Genom definitioner, benämningar och synonymer i data- och informationsmodeller (eller gärna rika informationsmodeller som integrerar fysiska och logiska aspekter).
- Verksamhetsbegrepp och terminologi
Genom definitioner, benämningar och synonymer i data- och informationsmodeller (eller gärna rika informationsmodeller som integrerar fysiska och logiska aspekter).
- Verksamhetsregler
Med verksamhetsregler i text och grafik i rika informationsmodeller.
- Datalogistik
Beskrivning av data-/informationsflöden genom verksamhetens förmågor, roller, applikationer, tjänster och externa parter, med hjälp av förmågekartor som är en karta över verksamheten.
- Datakrav och databehov
Möta intressenter och analysera deras behov, både nuvarande och framtida. Dessa hittar du i förmågekartan.
- Anskaffning/analys/insamling av nya data
Om någon del av verksamheten har behov av data som vi inte har tillgängligt idag behöver vi undersöka om möjligheten finns att få fram dessa. Det kan vara från externa eller interna källor.
Vad är en bra indelning?
När vi i olika sammanhang delar in saker och ting i meningsfulla och användbara grupper använder vi, medvetet eller omedvetet, vissa principer. Den viktigaste principen är nog den som kan kallas för decoupling, att sambanden mellan saker och ting inom gruppen är fler och tätare än mellan saker och ting i olika grupper. Särskilt behöver vi beakta det täta beroendet som dubbelriktade kopplingar innebär.
Skälet är att vi behöver ha en grad av oberoende mellan grupperna för att kunna hantera komplexiteten. Indelningen ska vara så att man ska kunna ändra en grupp utan att andra påverkas mer än absolut nödvändigt.
När vi pratar om samband kan det röra sig om samband av olika slag. Den viktigaste typen av samband är att ett ting (vad det än handlar om) refererar ett annat ting. Men det kan också vara andra aspekter som att ett visst objekt härrör från samma källa som ett annat. Vi behöver alltid sammanväga olika faktorer, både teoretiska och praktiska.
Vilka alternativa indelningsgrunder kan vi diskutera?
Vilken indelningsgrund ska vi då anamma? Följande tre alternativ brukas nämnas:
Ämnesområden
Argument: Vi utgår från de centrala begreppen som hanteras och tänker mindre på hur och var dessa data hanteras. Tanken är att exempelvis allt som har med kunder att göra bör vara en och samma domän, och allt som har med produkter att göra ska vara en annan domän.
Applikationer
Argument: Varje dataelement bör ha en viss applikation som är master, det vill säga är auktoritär källa för just det dataelementet. Då kan man argumentera för att det är lämpligt att datadomäner är mer eller mindre samma som applikationerna.
Verksamhetsförmågor
Argument: Vi tar fasta på att verksamhetens förmågor är de viktiga subjekten i verksamheten. En verksamhetsförmåga ansvarar för ”sina egna” data.
Jag vill visa att motiveringarna ovan visserligen inte är direkt fel, men att inte är helt färdigtänkt. Att ämnesområden, applikationer och verksamhetsförmågor i våra verksamheter har samband med varandra så att argumenten ovan inte står i konflikt med varandra. Låt oss gå igenom argumenten för varje alternativ indelningsgrund lite närmare.
Alternativ indelningsgrund: Ämnesområden
Jag tror att vi kan vara överens om att mycket talar för att vi ska ha datadomäner som var och en omfattar ett ämnesområde. Men då bör vi se upp med följande:
Komplikation 1: Bara för att något råkar ha ett och samma namn i verksamheten är det inte säkert att det verkligen bör ses som samma ämnesområde
Säg att vi säger att ”Kunder” är en domän. Det kan då vara att man har två helt olika kategorier av kunder som inte alls har med varandra att göra, och som har helt olika krav på säkerhet, kvalitet, typer av produkterbjudanden med mera.
Till exempel att en och samma verksamhet har både organisationer och privatpersoner som kunder, och att de kan sägas finns på olika marknader och köper olika tjänster och produkter. Då är det kanske inte lämpligt att se ”Kunder” som en enda domän utan vi bör dela ner området i flera domäner. På samma sätt kan det vara med produkter och tjänster. Vi kan ha två helt olika produkt- eller tjänsteområden med helt olika krav på vilken information som behövs och på vilket sätt det behöver hanteras.
Komplikation 2: Attribut som ytligt sett hör till samma entitet bör ibland ses höra till olika entiteter, ibland även till olika ämnesområden
Det kan vara så att en och samma entitet har attribut som tjänar helt andra syften än övriga och har helt annan källa och krav på sin hantering.
Exempel: Ett vanligt fall är kopplat till de krav man ställer på kundkännedom på finans- och försäkringsbolag för att förhindra penningtvätt med mera. Man kan då behöva hantera grunduppgifter om personer (till exempel personnummer och namn) för sig och de uppgifter som hör samman med en specifik roll till verksamheten för sig (till exempel vilken kund- eller anställningsstatus personen har). Det kan innebära att neutrala uppgifter om individer blir en domän och uppgifter som har med kundrelationen att göra en annan. En och samma entitet får då vissa attribut som hör till en domän och andra som hör till en annan.
Lösningen bör då vara att vi ser Person och Organisation som separata entiteter i ett särskilt ämnesområde som kanske heter ”Parter”. Entiteten Kund blir en annan entitet i ett annat ämnesområde som kanske heter ”Kunder”. Entiteten Kund beskriver då bara det som har med partens (personen eller organisationens) roll som kund hos oss, inte grunduppgifterna om personen eller organisationen som inte har med rollen att göra.
Dessa möjliga komplikationer kokar ner till att vi bör vara uppmärksamma på att bara för att något har ett och samma namn i verksamheten inte nödvändigtvis är samma entitet, eller ens hör till samma ämnesområde.
Om vi tar dessa hänsyn blir ämnesområden en bra indelningsgrund. Datadomänen kan då vara lika med ämnesområdet.
Alternativ indelningsgrund: Applikationer
En viss mängd data behöver ha en viss programvaruapplikation som är utpekad master, det vill säga auktoritär källa för just den datamängden. Då bör inte en och samma datadomän ha fler än en master. På så sätt blir en viss datadomän knuten till en viss applikation.
Fast det är i en del organisationer bara en målbild och inte så som verkligheten ser ut idag. Om man till exempel har slagit samman två företag med liknande verksamhet har man förmodligen samma typ av kunder i två olika applikationer under en övergångstid. Då bör man se ”Kunder” som att de utgör en och samma datadomän trots att de på grund av historiska skäl fortfarande råkar hanteras i olika applikationer.
För data som har en extern källa behöver man ändå peka ut en viss applikation som intern källa. Den applikationen bör ha ansvar för datakvaliteten, det vill säga vara ”gatekeeper”, upptäcka anomalier och larma för dessa, och även filtrera och transformera data till lämpligt internt format.
En och samma applikation kan ofta vara master för flera datadomäner.
Lägg märke till vad en applikation är. Det är inte samma som it-system. En applikation är per definition ett it-system, eller del av ett sådant som stöder en viss verksamhetsförmåga. Ett affärssystem är vanligen att se som ett ramverk med flera applikationer. Microsoft Excel är inte en applikation men däremot är den Excel-snurra som genererar månadsrapporten en applikation.
Alternativ indelningsgrund: Verksamhetsförmågor
Det finns en tydlig koppling mellan en applikation och en verksamhetsförmåga. En applikation innehåller alltid verksamhetslogik av något slag, och har alltid en verksamhetsförmåga som ansvarar för denna. Ja mer än så. Idag bör vi se en applikation som en integrerad del av en verksamhetsförmåga. Den tid är förbi då it var ett stöd till en verksamhet. Idag är it mer att se som en mer eller mindre (oftast mer) integrerad del av verksamheten.
Vi kan ofta hitta en applikation som inte ägs av en viss utpekad verksamhetsförmåga utan används av många verksamhetsförmågor, utan att kunna sägas ägas av någon. Då behöver vi de facto tala om att det finns en specifik verksamhetsförmåga, nämligen en stödförmåga som inte riktigt är uttalad och hanterad.
Den situationen är vanligt med masterdata, som till exempel kund- eller produktdata. Alla behöver relevant kund- och produktinformation men ofta vill ingen vill ta ansvar för hela verksamhetens behov av detta.
Per definition finns det emellertid alltid specifika verksamhetsförmågor som äger kund- och produktdata, för de hanteras ju de facto på något sätt, men förmodligen inte så bra hanterat och formaliserat som det behövs. Dessa förmågor finns inte i något organisationsschema utan är rudimentära, ofta dolda och okända.
Vår uppgift blir då att tydliggöra, formalisera och utveckla dessa förmågor. I praktiken innebär det att vi bygger upp en uttalad stödförmåga för en viss typ av datadomän.
Resultatet
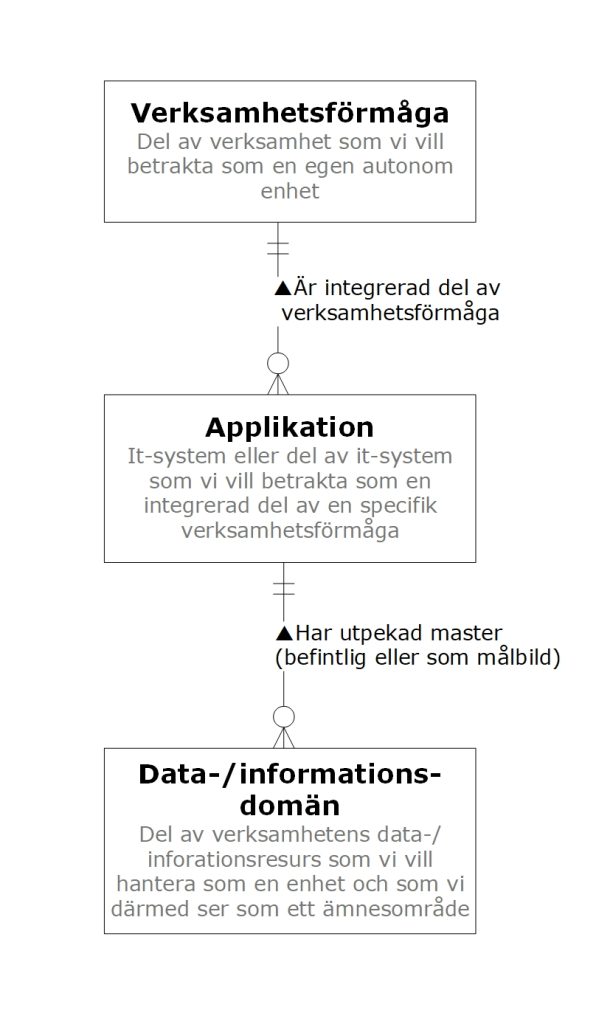
Resultatet av resonemanget i denna artikel blir då följande metamodell. Se illustration.
- En data-/informationsdomän är ett ämnesområde, fast där man tagit hänsyn till att ett ämnesområde inte bara är något som råkar ha samma vardagliga namn i verksamheten utan också är något som har krav på sammanhållen hantering.
- En data-/informationsdomän bör alltid ha endast en applikation som utpekad master. Åtminstone bör målbilden vara så.
- En applikation hör alltid (definitionsmässigt) till endast en verksamhetsförmåga. Applikationen bör ses som en integrerad del av verksamhetsförmågan och inte bara att den ”stödjer” verksamhetsförmågan i fråga.Verksamhetsförmågan kan vara outtalad, men finns egentligen alltid där, och vi bör se till att den blir tydlig och etablerad.
På så sätt kan vi beakta både att vi behöver se en datadomän som ett ämnesområde och att vi också behöver beakta var ämnesområdets data hanteras (applikation) och och var i verksamheten ansvaret ska finnas (verksamhetsförmåga).
Det finns säkert fler aspekter att beakta. Berätta gärna om dina erfarenheter.
PS: Glöm inte ”ostrukturerad” information.
Hela det här resonemanget har bara berört den information som finns i strukturerad form, det vill säga i tabeller eller liknande. Den mesta informationen i en verksamhet finns i annan form, som texter, dokument och även bild, film och ljud. Vi kallar den informationen för ”ostrukturerad”, fast egentligen är den bara strukturerad på ett annat sätt. Även denna information bör hanteras. Men det är en annan historia.
