Informationsmodellering: Kan vi samla olika perspektiv i en och samma modell?
Som informationsarkitekt behöver vi hantera data och information ur flera perspektiv, de som ofta kallats konceptuellt, logiskt och fysiskt perspektiv. Traditionellt har man försökt göra detta genom att ta fram flera modeller, en för varje perspektiv. Men det finns ett bättre sätt – att samla allt i en och samma modell.
/Peter Tallungs, IRM, 2025-10-09
Olika perspektiv på samma information
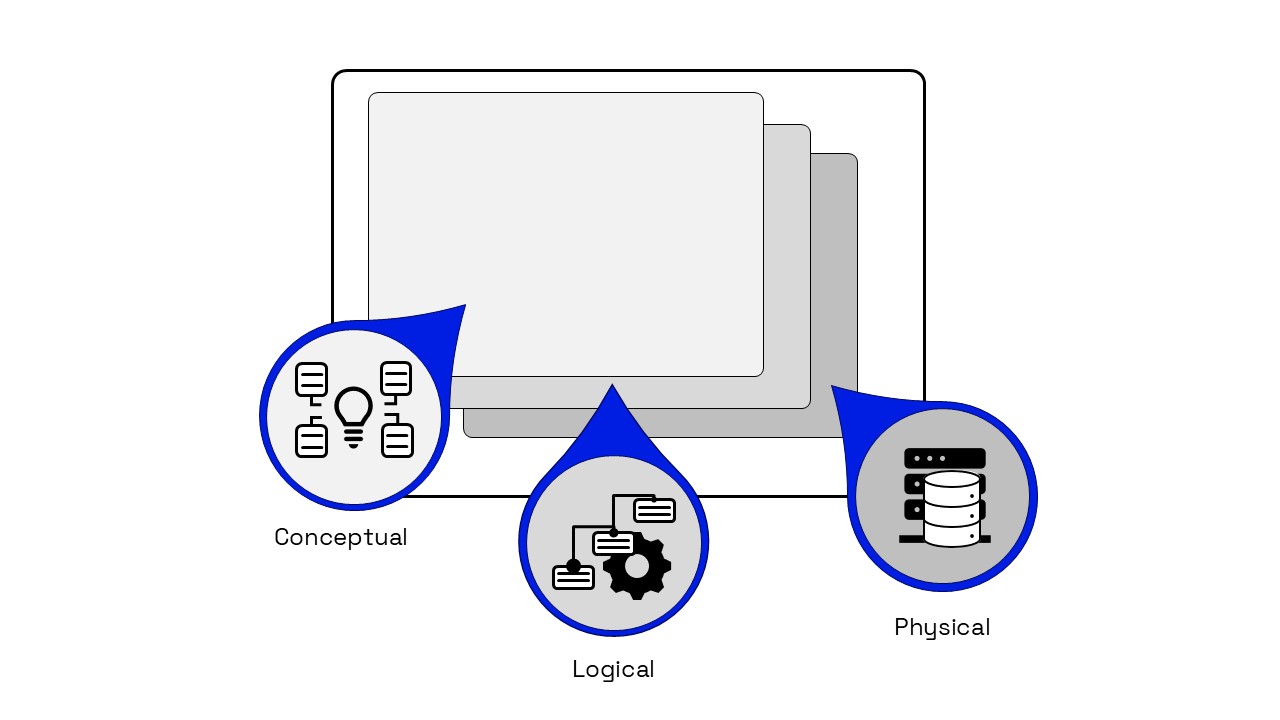
När man tagit fram informationsmodeller har man traditionellt delat in dessa efter vilket perspektiv man beskrivit informationen ur. Det finns flera varianter, men den vanliga indelningen är följande:
Konceptuell informationsmodell (Conceptual data model)
En konceptuell informationsmodell beskriver semantiken för hur vi vill att människor ska förstå och prata om företeelserna inom ett visst område, inklusive deras egenskaper och relationer. Modellen består av entitetsklasser (som representerar de typer av företeelser som har betydelse) med attribut (som representerar företeelsernas egenskaper) samt relationer mellan entitetsklasserna (som representerar informationsmässiga samband som finns mellan företeelserna).
Syftet med den konceptuella modellen är att definiera vilka typer av fakta man ska kunna uttrycka inom området, det vill säga vilket språk vi behöver för att prata om ämnet.
Den konceptuella informationsmodellen är till syftet besläktad med det som ibland kallas en begreppsmodell (concept model). De används båda för att beskriva begrepp. Men det finns en viktig skillnad: I en begreppsmodell uttrycker relationerna hur begrepp definieras i termer av andra begrepp. Medan relationerna i en informationsmodell uttrycker hur företeelser relaterar till varandra informationsmässigt, nämligen hur värdet på en egenskap (ett attribut) hos en typ av företeelse (entitet) kan definieras i termer av förekomster hos annan typ av företeelse (entitet).
Logisk informationsmodell (Logical data model)
En logisk informationsmodell beskriver semantiken för hantering eller lagring av en informationsmängd (till exempel i en databas, fil eller via ett API) fast utan att förutsätta någon specifik datahanteringsteknik. Den liknar den konceptuella modellen, men är mer inriktad på en tänkt systemlösning, som ett informationssystem eller en komponent i ett sådant.
Fysisk informationsmodell (Physical data model)
En fysisk informationsmodell, ofta kallad datamodell, beskriver hur informationen faktiskt lagras eller hanteras, så som detta framträder för databas- eller progranvaruutvecklaren.
Modellen kan bestå av till exempel databastabeller och kolumner, klasser och attribut inom objektorienterad systemutveckling, XML-taggar eller liknande strukturer.
(Ibland menar man med en datamodell det som är ännu mer fysiskt, till exempel filstruktur eller lagringsformat. Men det är ett perspektiv som mest berör dem som bygger eller analyserar olika datahanteringstekniker, vilket inte är ämnet här.)
Det finns som sagt flera varianter på hur man gör den här uppdelningen. Ibland slås logisk och fysisk modell ihop. Men grundbehovet är detsamma: vi behöver kunna beskriva samma information ur flera olika perspektiv, samtidigt.
Tanken är att dessa perspektiv ska vara någorlunda oberoende av varandra. Man ska till exempel kunna byta teknik för datalagring utan att alltid behöva ändra i den logiska modellen, och ej heller i den konceptuella.
Problemet med att ha separata modeller för olika perspektiv på samma företeelser
Att ta fram och underhålla tre separata modeller för samma informationsmängd (en konceptuell, en logisk och en fysisk) har ett pris. Och det är ett pris man sällan vill betala. I praktiken är det ovanligt att modeller för alla de tre perspektiven faktiskt tas fram och ännu mera sällsynt att de fortsätter att underhållas över tid.
Om man verkligen skulle hantera sin verksamhet och informationsteknik på detta sätt, så innebär det inte bara att tre modeller måste hållas uppdaterade, utan också att alla kopplingar mellan dem måste vidmakthållas. För modellerna måste vara konsistenta med varandra. Man vill enkelt kunna följa spåret Hur ser företeelserna ut för verksamheten, och hur representeras dessa som data i it-miljön.
Även om man skulle orka hålla modellerna i synk så återstår ett problem, och det är att överblicken går förlorad. När man har olika modeller för samma sak underhåller man också olika mentala bilder av hur verksamhetens information egentligen ser ut och är strukturerad. Då blir det friktion i kommunikationen, särskilt mellan it och verksamhet.
Det låter kanske enkelt att översätta mellan modeller, men tänk att behöva göra det hela tiden, i varje användargränssnitt, i varje rapport och i varje mänsklig dialog mellan it- och verksamhetsfolk. Ofta rör det sig om flera tusen begrepp, ofta dåligt namngivna och bristfälligt definierade. Det är en börda att släpa på.
Problemet med underhåll av flera modeller har man visserligen ofta sluppit undan genom att man haft en idé om att den konceptuella modellen kan stanna vid att vara mycket grov och översiktlig. För att först senare detaljeras och förfinas i den logiska modellen och än mer i den fysiska modellen. Detta synsätt stämmer med den allmänna betydelsen av termen konceptuell modell inom andra områden, som till exempel ingenjörsarbete. Där är betydelsen av en konceptuell modell att den endast visar en första översiktlig skiss, en idé.
Men för informationsmodeller är det, enligt min mening, en dålig idé, vilket jag ämnar argumentera för i denna artikel.
Betydelsen av en gemensam förståelse och ett gemensamt språk
Det är ett grundläggande felgrepp, menar jag, att inte utveckla och underhålla en gemensam förståelse bland alla berörda. Att tro att man kan klara sig utan ett gemensamt språk för verksamhetens företeelser, i alla dess intrikata detaljer.
Om vi nöjer oss med sådana överförenklade konceptuella modeller får det konsekvenser. Viktig semantik hamnar i programkod och datastrukturer, där den blir otillgänglig för andra än systemutvecklare och databasdesigners. Informationen blir svår att överblicka och riskerar att glömmas bort.
Det stora problemet med att arbeta med flera olika modeller för samma informationsmängd på detta sätt är att det hindrar den kraft vi kan få av våra modeller. Nämligen att och bygga en gemensam syn för alla intressenter. Att ha en gemensam karta och ett gemensamt språk. Och att samla olika perspektiv i en och samma vy, så vi kan se samband.
Denna brist får större konsekvenserna än man kanske anar. Utan gemensamma begrepp och ett gemensamt språk saknar verksamheten både plattform och arbetssätt för att bygga förståelse tvärs över gränserna i organisationen.
Vi behöver modellera i fullständig detalj
Den ursprungliga tanken bakom att arbeta med olika modellperspektiv, som bland annat uttryckts av John Zachman, fadern till mycket inom området, var att varje perspektiv skulle utvecklas med fullständig detaljeringsgrad. (Hans formulering var ”excruciating level of detail”, vilket kan översättas med ”plågsam detaljeringsgrad”.
Och jag håller verkligen med honom. Översiktliga modeller är trubbiga verktyg. Våra modeller måste klara av att hantera alla detaljer i verksamhetens operativa logik. The devil is in the details.
Det bör alltså inte finnas någon skillnad i detaljeringsgrad mellan perspektiven. Alla behöver vara lika detaljerade och genomarbetade. Men de kan rymmas i en och samma vy. Låt oss titta närmare på detta.
Kan vi samla flera perspektiv i samma modell?
Vad krävs för att vi ska kunna slippa att ha olika modeller för samma informationsmängd? Vi kommer inte undan att vi behöver se informationen ur olika perspektiv. Vad behövs för att samla flera perspektiv i en och samma modellvy?
För att besvara det behöver vi ställa oss två frågor:
För det första:
Behöver de olika perspektiven vara så olika? Är det helt olika strukturer och begreppsvärldar som svårligen låter sig samlas i en och samma vy? Eller handlar det om mindre skillnader, som att en och samma entitet ibland är spridd över fler tabeller? Eller att man har olika benämningar för samma sak, det vill säga att de som byggt it-systemen använt namn som inte stämmer med vad som fungerar som ett gemensamt verksamhetsspråk?
För det andra:
Kan vi rent grafiskt gestalta flera perspektiv i samma vy? Till exempel genom att använda färger, typsnitt eller andra visuella medel för att tydligt skilja ut perspektiven från varandra? Så att vi mer eller mindre friktionsfritt kan hantera de skillnader som trots alls finns.
Jag menar att svaret på båda frågorna är ja, det går. Men då måste vi släppa några gamla föreställningar som hindrar oss.
Hur mycket behöver perspektiven skilja sig?
De finns en gammal tro på att benämningar och datastrukturen i ett it-system, av tekniska skäl, behöver vara olik den bild som verksamhetsfolket behöver ha i huvudet. Men skillnaden behöver faktiskt inte vara speciellt stor. Den bör egentligen vara så liten om möjligt, och i stort sett försumbar.
Operativa och analytiska it-system har olika struktur
Hur stora skillnaderna behöver vara beror till viss del på vilken typ av it-system vi talar om. Ty det är skillnad på strukturerna i operativa respektive analytiska system.
Operativa system
Det vill säga de systemen där verksamheten faktiskt opereras i mer eller mindre realtid. Transaktionssystem, så kallade system of records, där man löpande lägger till, raderar eller uppdaterar enstaka poster för att representera vad som händer i verksamheten just nu.
Analytiska system
De flesta lite större verksamheter behöver dessutom analytiska system, till exempel data warehouses eller business intelligence-lösningar, där man kan följa upp och analysera vad som hänt över tid. Det är system dit man varje natt tankar över nya och förändrade data från de operativa systemen. Dessa system fungerar som verksamhetens uppföljning. Data uppdateras i batch där analytiker sedan kan vända och vrida på stora mängder information för att sammanställa analyser och rapporter hur verksamheten utvecklas över tid.
Dessa två typer av system ställer olika krav på datastrukturer, men dessa datastrukturer kan och bör ha en grund i den gemensamma konceptuella modellen, som ska representera den gemensamma förståelsen och det gemensamma språket, tvärs över organisations- och teknikgränser.
It-systemens modell bör vara identisk med verksamhetens modell
Om vi först begränsar diskussionen till de operativa systemen, finns det ett modernare synsätt än idén om att vi behöver tre separata strukturer.
Detta synsätt formulerade Eric Evans redan 2003 i den inflytelserika boken Domain-Driven Design. Den bärande idén där är att den del av programkoden i ett objektorienterat system som representerar själva domänen, det vill säga allt det i verksamheten som systemet hanterar eller interagerar med på något sätt, bör utformas så likt verksamhetens egen förståelse som möjligt. Ett synsätt där man i största möjliga utsträckning ska låta de tre perspektiven vara så lika som möjligt.
Det gäller både struktur, namngivning och vilket nationellt språk man använder.
Evans bok handlar om hur man kan designa programkod för att representera domänen, men synsättet är lika tillämpbart på system där det är strukturen i en databas som representerar domänen och inte klasstrukturen i programkoden.
Eric Evans uttryckte det så här:
Om några personer sitter runt ett bord och du hör dem prata om ”kunder”, ”avtal” och ”betalningar”, så ska du först inte riktigt kunna avgöra om de pratar om verksamheten, eller om programkoden.
Och det är precis så det bör vara.
Du kan läsa mer om det i artikeln: Ur informationsarkitektens bokhylla – del 4: Om informationsmodelleringens strategi.
Vi behöver en gemensam modell
Det handlar alltså om att verksamhet och it ska dela samma modell, samma språk, så långt det bara är möjligt. Och det är faktiskt möjligt att komma betydligt längre än vad som är brukligt i våra organisationer idag. Konkret innebär det att den del programkoden som representerar verksamhetens företeelser bör följa samma struktur och namngivning som vi har i vår gemensamma modell.
Modellen fungerar då som ett gemensamt språk, med gemensamma benämningar, en gemensam förståelse, som vi tar fram och utvecklar vidare tillsammans.
Traditionellt har annars många it-utvecklare resonerat så här: Vi använder ett mer tekniskt språk internt i it-systemet, för att sedan översätta till vad verksamheten vill att det ska heta i användargränssnitt och rapporter.
Det kan låta rimligt. Men tänk efter. Varje liten punkt där översättning ska ske ger lite (måhända knappt märkbar) kommunikativ friktion. Och lite friktion på tusen ställen blir snabbt mycket friktion. Det skaver i varje dialog mellan verksamhet och it, för all översiktlig framtid.
Det handlar inte bara om olika termer för samma sak, utan ofta rör det sig om helt olika strukturer i de olika modellerna.
Och då blir det svårt att kommunicera. Svårt att förstå varandra. Och svårt att bygga system som faktiskt stödjer verksamheten
It-systemen bör ses som fullt integrerade komponenter i verksamheten
Jag förespråkar att vi bör se våra it-system som fullt integrerade delar av våra verksamheter, inte som något vid sidan av. Och det minsta vi kan göra i den andan är att jobba för ett gemensamt språk och en gemensam förståelse kring allt det vi hanterar. Det är där vi som informationsarkitekter har ett särskilt ansvar.
Eric Evans går ett steg längre. Han menar att det är så avgörande att datastrukturen i it-systemen speglar verksamhetens syn på de företeelser som data representerar att man ibland behöver möta varandra halvvägs.
Det kan betyda att vi som utvecklar system ibland får välja en struktur i databas eller programkod som kanske inte är den tekniskt optimala, men som stämmer överens med verksamhetens begreppsvärld. Och det kan också betyda att verksamheten ibland får anpassa sig lite till hur företeelserna faktiskt är strukturerade i systemen.
Men det handlar i så fall om små och få undantag, och bara där det verkligen inte går att undvika.
Kan vi samla skilda perspektiv i samma modell?
Om det trots allt finns skillnader mellan hur vi i verksamheten ser på domänen och hur denna domän faktiskt är implementerad i våra system, kan vi då ändå samla dessa perspektiv i en och samma vy?
Om man utgår från det synsätt som Eric Evans presenterar i Domain Driven Design, så är skillnaden liten.
Men verkligheten ser för det mesta annorlunda ut. Många verksamheter sitter med system, där i stort sett allt heter saker som inte fungerar som ett tydligt verksamhetsspråk, eller ens som ett begripligt språk över huvud taget. Ofta är det bara den stackars programmerarens första gissning.
Ofta finns det också strukturella skillnader. Information om exempelvis kunder kan ligga utspridd över flera tabeller utan tydlig sammanhållning. Och ibland har man slagit ihop olika typer av uppgifter som man egentligen borde hålla isär. Då kan vi inte ha en och samma struktur och samma benämningar tvärs över de olika perspektiven. Men vi kan ändå samla flera perspektiv, inte bara i samma modell utan till och med i samma modellvy.
Nyutveckling eller befintliga system
Jag och mina kollegor har de senaste 20+ åren arbetat med att ta fram informationsmodeller som kan härbärgera flera perspektiv i en och samma vy. Våra erfarenheter är mycket goda, men det kräver att man gör upp med en del etablerade ”sanningar” och arbetssätt i it-världen.
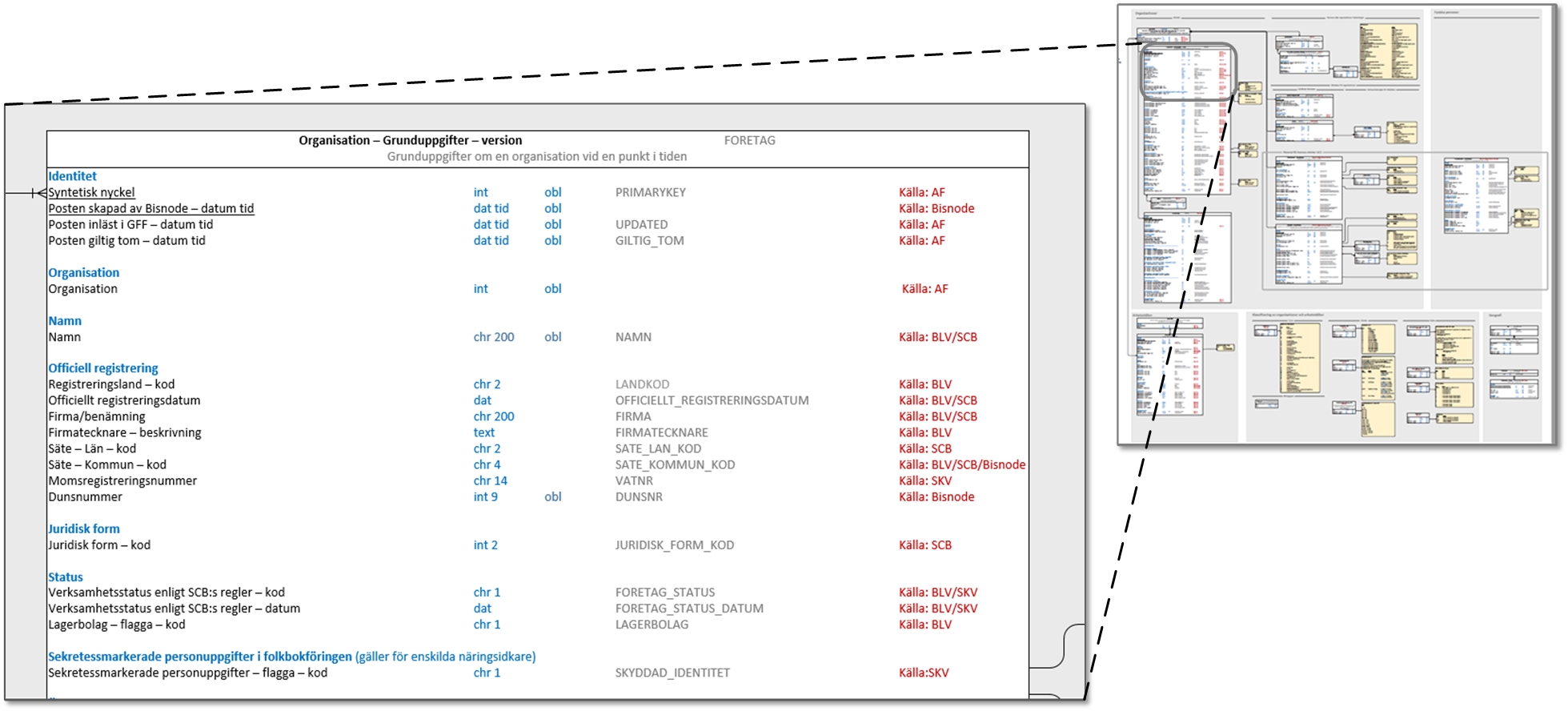
Modellerna vi tar fram är i grunden konceptuella, med vilket vi menar att de representerar ett gemensamt språk tvärs över verksamhet och it. Samtidigt visar vi i samma vy även den motsvarande fysiska strukturen. Det vill säga hur informationen representeras i databaser, tabeller och kolumner. Alltså två olika perspektiv i en och samma vy. Vi använder grafikens möjligheter som färger och former för att tydligt skilja perspektiven åt.
I det fall man tar fram en helt ny it-lösning blir perspektiven mycket lika, det vill säga att det konceptuella och fysiska perspektivet blir i stort sett desamma. Då blir det enkelt, samma språk i modeller, i databasen, i användargränssnitt och i dialogen mellan verksamhet och utveckling.
När man modellerar befintliga lösningar skiljer sig perspektiven ofta kraftigt åt. Nästan alla databastabeller och kolumner eller motsvarande har namn som inte fungerar som ett tydligt och korrekt gemensamt språk. Och datastrukturerna är ofta bristfälligt dokumenterade, ibland nästan obegripliga.
Det går relativt lätt att ta fram en gemensam modell som både utgör ett effektivt och tydligt verksamhetspråk och samtidigt beskriver var och hur verksamhetens data hanteras och lagras.
Observera att de konceptuella och fysiska perspektiven ska samlas i samma vy, inte i skilda vyer i en samma modell. Det vill säga att man samtidigt ska kunna se och jämföra de olika perspektiven utan att behöva skifta mellan olika bilder.
Det är svårt att överskatta värdet av en sådan samlad vy. Det gör skillnad i kommunikationen och arbetssättet mellan verksamhets- och it-experter.
Analytiska system behöver kompletterande strukturer
Jag skrev tidigare att en fysisk datastruktur inte nödvändigtvis behöver skilja sig från den konceptuella. Det är sant för operativa system, men de analytiska systemen ställer delvis andra krav.
Begrepp, namn, definitioner och verksamhetsregler bör fortfarande följa den konceptuella modellen som ju är det korrekta gemensamma överenskomna språket. Men däremot behöver man ha helt andra strukturer på data. Man behöver oftast ha minst två skilda fysiska strukturer i dessa system. Dels behöver man en lagringsstruktur som är hållbar över tid, det vill säga så flexibel att den klarar schemaändringar i källsystemen som ju är de operativa systemen.
Man behöver två olika fysiska strukturer i de analytiska systemen.
En lagringsstruktur som är hållbar över tid
Eftersom data i de analytiska systemen ska finnas kvar i många år, måste strukturen kunna hantera de ändringar i informationsstrukturen som alltid sker i det långa loppet. Det kan till exempel vara en omorganisation, där det annars blir svårt att följa upp försäljningssiffror kopplade till organisationsenheter när tillhörigheten för folk och enheter kastats om. För att hantera detta använder man någon av de särskilda dataarkitekturer, tåliga för förändringar, som finns för ändamålet, till exempel Data Vault.
En presentationsstruktur för analytiska användare
De som ska använda de analytiska systemen behöver en annan datastruktur. En som är särskilt anpassad för att enkelt kunna betrakta och konsolidera data ur olika perspektiv. För detta använder man så kallade dimensionsmodeller, även kallade stjärnmodeller (eller star schemas).
Vi vill gärna höra dina tankar
Vi vill gärna dela med oss av våra erfarenheter, och tar minst lika gärna del av dina. Om ämnet väcker tankar eller frågor, eller om du själv arbetar med att utveckla bättre arbetssätt med informationsmodeller, hör av dig! Vi tror på dialog och gemensam utforskning.

Få ett mejl när ny artikel om informationsarkitektur är ute

Ska vi prata vidare?
Fyll i formuläret så hörs vi! Peter Tallungs, informationsarkitekt