Vad kommer först, ontologi eller informationsmodell?
Hur förhåller sig en ontologi till en informationsmodell? Vilken ska vi ta fram först?
/Peter Tallungs, IRM, 2025-11-06
Ontologier: The new kids on the block
En del organisationer har börjat ta fram den typ av begreppsmodeller som kallas ontologier. Men vad är egentligen en ontologi, och hur förhåller sig en sådan till de informationsmodeller vi brukar ta fram? Detta vill jag resonera om i denna artikel.
Ontologier och informationsmodeller har båda beroenden till varandra och delvis överlappande syfte. Men först vill jag flagga för att man kan mena ganska olika saker med en ontologi. Och samma sak gäller en informationsmodell, både syfte och utformning kan variera stort.
Dessutom: Hur dessa typer av modeller faktiskt ser ut och används i praktiken skiljer sig från hur de beskrivs i teorin. Vi börjar med en teoretisk jämförelse.
Vad är en ontologi?
Ontologin är ursprungligen namnet på en gren inom filosofin, läran om varandet. Det vill säga existensens natur. Man studerar vad som finns i världen, dess grundläggande kategorier och hur saker är relaterade till varandra. Man strävar helt enkelt efter att förstå världen.
Men inom dataområdet har termen ontologi, även kallad data ontology, fått en mer praktisk betydelse. Ontologi är då inte en lära utan en typ av modell man kan ta fram.
En ontologi är i detta sammanhang en formaliserad beskrivning av en domän, det vill säga ett ämnesområde av något slag. En ontologi beskriver företeelserna inom den domän man är intresserad av med sina egenskaper och relationer definierade med relevanta begrepp och termer. Syftet är att skapa ett gemensamt språk och en gemensam förståelse av domänen.
Domänen kan till exempel vara en viss verksamhetsfunktion i en verksamhet, en hel verksamhet, en viss aspekt av en verksamhet eller en bransch. En ontologi har således samma syfte som en begreppsmodell, även om den kan ha en annan detaljutformning.
Hur skiljer sig en ontologi från en informationsmodell?
Hur skiljer sig då en ontologi från en informationsmodell? Det beror på vad man menar med informationsmodell. En traditionell definition av en informationsmodell säger följande:
En informationsmodell är en ritning som definierar struktur, relationer och regler för data i ett system eller en domän. Den organiserar informationen genom att specificera dess komponenter, deras egenskaper och hur de hänger ihop. Modellen hjälper oss att skapa en gemensam förståelse och struktur för data, och vi kan använda den för exempelvis programvaruutveckling och datahantering.
Enligt dessa definitioner beskriver en ontologi en domän medan en informationsmodell för samma domän beskriver data som representerar domänen.
Ontologin borde alltså komma före informationsmodellen – åtminstone i teorin.
Ty först måste vi reda ut företeelser och begrepp, och därefter, utifrån denna förståelse tillsammans med hur vi förstår informationsbehoven, strukturera data som ska representera dessa företeelser.
Men i praktiken fungerar det nästan alltid tvärt om.
Det är sant att vi inte kan namnge, definiera och strukturera data utan förståelse för vad dessa data ska representera. Men de typer av formella ontologier som används idag är inte särskilt lämpade för arbetet med att skapa denna förståelse. Ty för att bygga, utveckla och förmedla en gemensam förståelse, med allt vad detta innebär, krävs att man gemensamt arbetar runt ett rikt grafiskt och textuellt format. Och det är inget de standarder som används för formella ontologier ger möjlighet till.
Å andra sidan är det just här informationsmodeller glänser, i varje fall om man gör på rätt sätt beträffande gestaltning och arbetsformer. Informationsmodellen är i praktiken det bästa verktyget vi har för att tillsammans reda ut, dokumentera, och förmedla företeelser, begrepp och språk.
Därför menar jag att det i verkligheten ofta är den omvända ordningen som gäller:
Först arbetar vi med och runt informationsmodellen – och först därefter kan vi, om det behövs, kodifiera resultatet i form av en formell ontologi.
Från teori till praktik
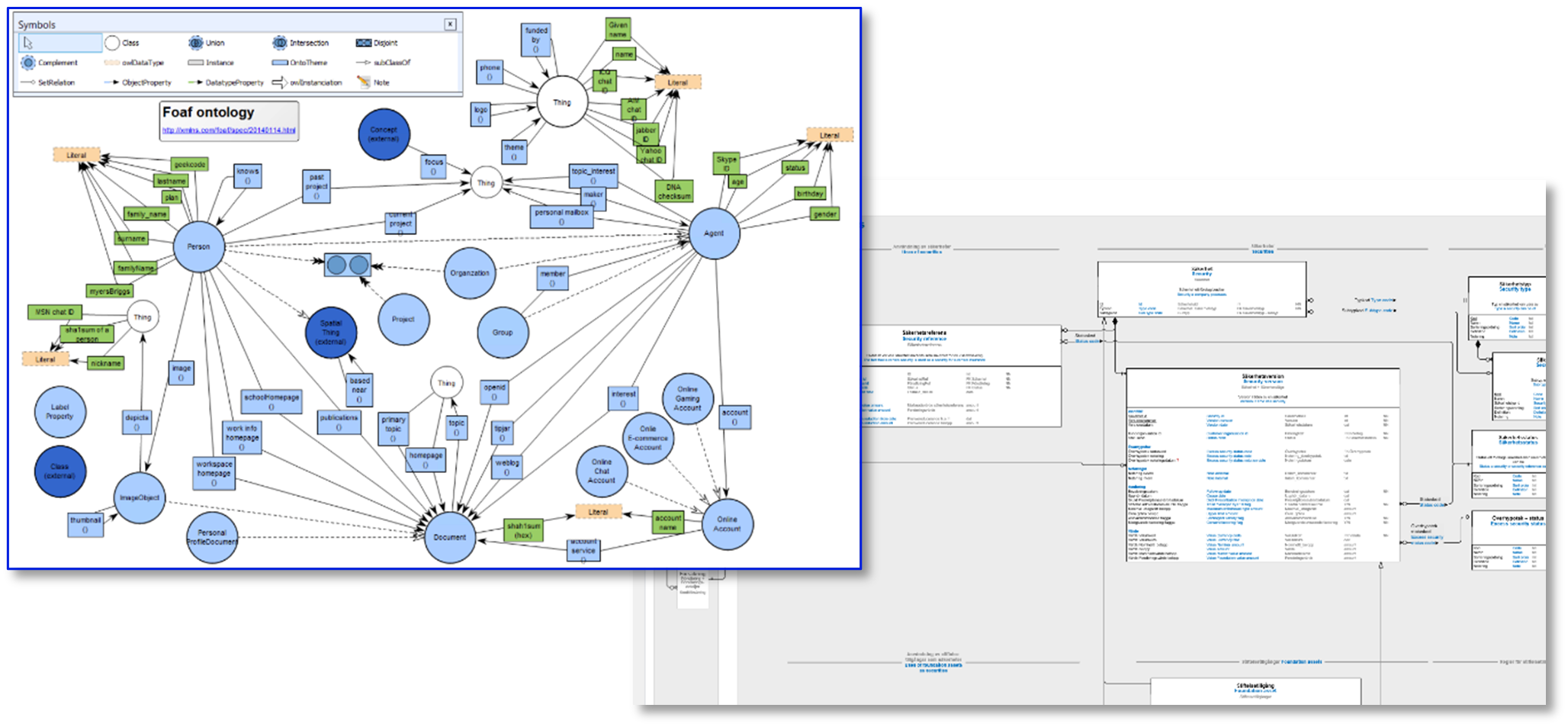
Låt mig förklara vad jag menar. Det handlar om att de ontologier som tillämpas i våra organisationer nästan alltid är formella ontologier, det vill säga modeller framtagna för maskinläsbarhet, och därmed inte särskilt lämpade att arbeta med för att bygga gemensam förståelse mellan människor.
Man använder då något av de standardiserade format som finns, till exempel OWL (Web Ontology Language) eller RDF (Resource Description Framework). Dessa format är utformade för att kodifiera begrepp och relationer i en domän på ett sätt som maskiner kan tolka, exempelvis för AI-tillämpningar, sökoptimering eller automatiserad beslutslogik.
Men när vi ska bygga ett gemensamt normerat språk för en domän så är det enligt min mening inte framkomligt att börja direkt i ett sådant format. Arbetet kräver något helt annat.
Vi behöver åskådliggöra, illustrera, hantera, exemplifiera, dokumentera, samordna begrepp och regler, och göra detta löpande över tiden, tillsammans med olika verksamhetskunniga.
För detta behöver vi lämpliga verktyg och arbetssätt, som ger rikare uttrycksmöjligheter, med grafik och text. Först därefter kan vi, om så behövs, kodifiera resultatet till ett maskinläsbart format, det vill säga i en formell ontologi av ovannämnda slag.
Att ta fram en formell ontologi bör därför ses som en slags manuell kompilering av kunskap vi redan samlat in, utvecklat och beskrivit – inte som själva vägen till förståelsen.
Kopplingen mellan domän och data
Men behöver vi ändå inte först arbeta med domänens begrepp för att först därefter ta fram krav på datastrukturer? Bör vi inte tydligt skilja på beskrivningen av verkligheten och beskrivningen av data?
Nej. Jag menar att i verkligheten fungerar det sällan så enkelt och linjärt. Verkligheten är mer dynamisk än så. Det är svårt, och ofta direkt olämpligt, att försöka hålla arbetet med datastrukturer åtskilt från arbetet med verksamhetens begrepp, regler och språk.
Det finns visserligen situationer då vi kan fokusera på enbart den ena av dessa två aspekter. Men i de flesta fall behöver vi växla sömlöst mellan dessa två perspektiv. Och nästan alltid behöver vi samtidigt jämföra, beakta och hantera båda perspektiven.
Data för en viss domän representerar alltid domänens företeelser, inklusive dess egenskaper, regler och relationer. Måhända finns det avvikelser mellan datastrukturen och hur saker hänger ihop i domänen, måhända är termer dåligt namngivna och definierade, måhända är många regler underförstådda och dåligt dokumenterade. Men ändå så finns det alltid en koppling mellan domänen i sig och de data som ska spegla domänen. Kopplingen är kanske bristfälligt dokumenterad men den finns alltid där och är mestadels enkel och rak, om man bara undersöker den. Och det bör vi alltid göra för att förstå och dokumentera.
I en ideal värld vore skillnaden inte så stor mellan domänens företeelser och hur de är representerade i data, ty de är högst önskvärt att vi designar datastrukturer så de rakare och enklare representerar det som de ska representera. Men så är det sällan. Bristerna mellan data och verklighet finns därute i våra verksamheter. Man har ofta strukturerat och namngett data missvisande och slarvigt. Vi har tyvärr haft generationer av systemutveckling då man tyckt att de var en bra idé att separera it-utveckling från arbetet med att skapa gemensam verksamhetsförståelse. Det är en teknisk skuld vi nu får leva med och behöver hantera.
Data och det data representerar är som två kommunicerande kärl, där det ofta inte går att säga vad som kommer först. Vi behöver därför arbeta med två perspektiv samtidigt. Vi bör göra det i en och samma modell, ja till och med i samma vy.
Det är just där styrkan finns. När it och verksamhet tillsammans kan arbeta i en modell där man både ser strukturen i data och förstår vad den betyder. Då bygger vi gemensam förståelse, minskar friktion och ökar effektiviteten i hela organisationen.
Men blir de inte för rörigt att blanda perspektiv?
Man kanske vill invända: Behöver vi inte hålla isär saker för att det inte ska bli rörigt? Är det verkligen klokt att blanda domänmodell och datamodell i samma vy?
Nej, tvärt om, menar jag. Det är just i det gemensamma som styrkan ligger.
Alla riktigt intressanta modeller och diagram är multidimensionella. De sammanför olika typer av information i samma vy, och gör det utan att tappa överblicken.
Tänk på en geografisk karta. Den visar samtidigt topografi (berg, sjöar, höjdkurvor), infrastruktur (vägar, järnvägar), politiska gränser (kommuner, län, länder) och ibland också information om klimat eller befolkningstäthet. Allt i samma bild. Och detta utan att försaka vare sig överblick eller detalj. Nyckeln är att man kunnigt använder sig av grafikens möjligheter, med linjetjocklekar, gråskalor, färger, text, typsnitt och symboler.
Vi kan bli bättre!
Men hur gör vi för att skapa en modell som i samma vy visar både verksamhetens företeelser och språk, och de data som representerar dessa företeelser?
Det kräver att vi blir bättre på gestaltning av modeller. Lika skickliga som ingenjörer, konstruktörer och arkitekter är på sina ritningar, behöver vi bli på våra.
Informationsarkitekturen måste utvecklas. Vi kan inte längre skylla på att vi är en ung disciplin. Arbetet med informationsmodeller har pågått i snart ett halvt sekel, och ofta på ungefär samma sätt som vi gjorde på 1970-talet.
Vi behöver bli bättre på vårt hantverk. Det handlar om att:
- strukturera och disponera våra ER-diagram tydligare
- kombinera med andra diagramtyper, som tillståndsdiagram och förekomstdiagram för sådant som ER-diagram inte är bra på
- använda gråskala, färg och typsnitt för att skilja på aspekter
- kombinera bild och text i en sammanhängande helhet.
Ett stort hinder är verktygen. De flesta specialiserade modelleringsverktyg ger oss mycket begränsade möjligheter till grafisk och textuell gestaltning. Om vi nöjer oss med det, reduceras vår roll till operatörer av ett verktyg snarare än hantverkare som väljer verktyg som gör det jobb vi behöver göra. Då blir vi fångar i våra verktyg, i stället för att låta verktygen tjäna oss.
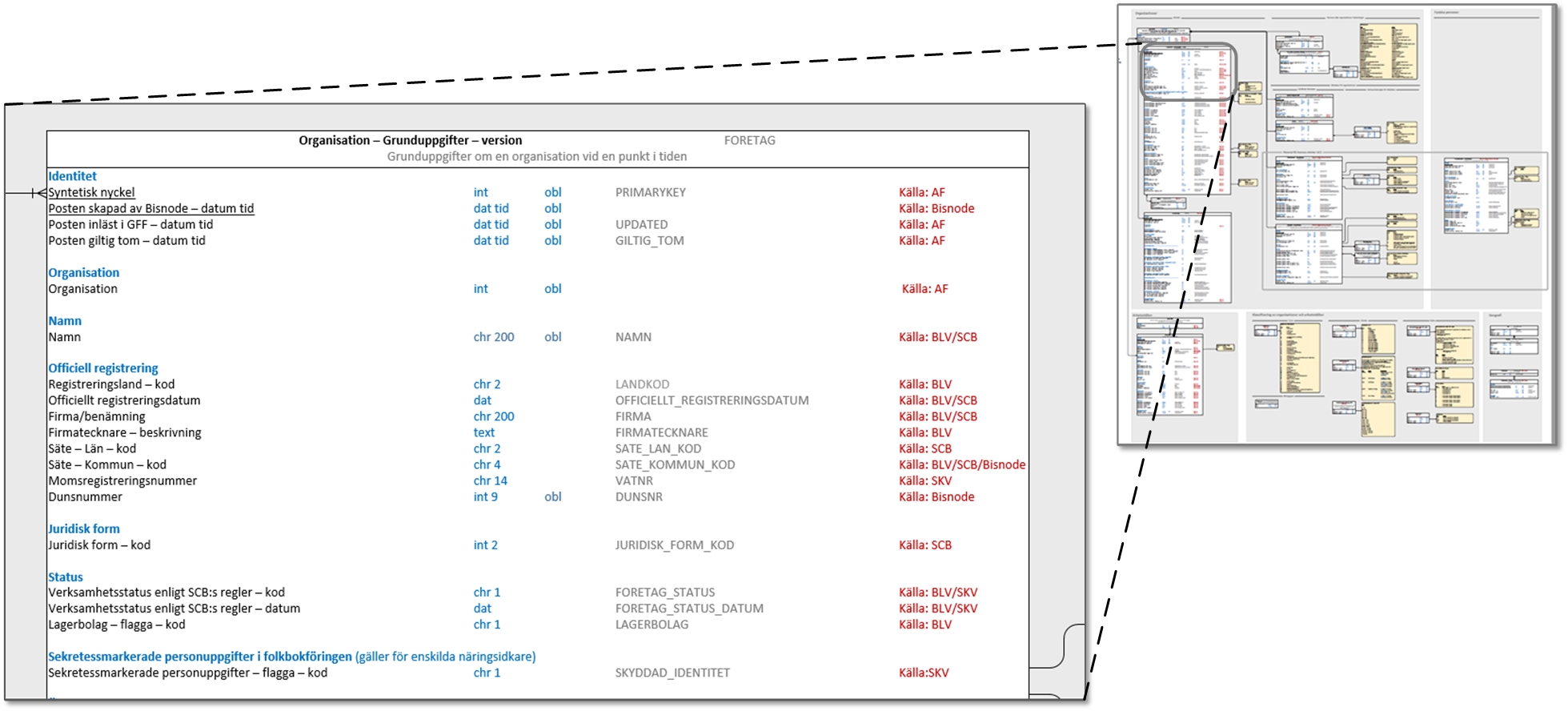
Jag och mina kollegor har utvecklat det vi kallar rika informationsmodeller. Det vill säga informationsmodeller som uttrycker betydligt mer än de traditionella, och gör det på ett bättre sätt.
En rik informationsmodell beskriver både själva domänen och de data som representerar domänens företeelser i databaser, filer och system. Den gör detta genom att kombinera olika typer av grafik och strukturerad text. Modellen fungerar därmed som både ontologi och informations-/datamodell, men är inte direkt maskinläsbar. Vill man ha det, behöver man fånga det man tagit fram i en formell ontologi.
Det här sättet att arbeta är beprövat. Vi använder det i våra uppdrag, och vi lär ut det på våra kurser.
Vad är din erfarenhet?
Du som arbetar med formella ontologier – hur gör ni för att samla in och strukturera den kunskap som ontologin bygger på? Gör ni det direkt i ontologin? Eller bygger ni först upp den gemensamma förståelsen i en annan typ av modell, till exempel en informationsmodell eller begreppsmodell?
Jag tror vi alla har mycket att vinna på att jämföra arbetssätt och inspireras av varandra. Vi som arbetar med att fånga, förtydliga och dela verksamhetens språk och struktur arbetar ju i själva verket med något som är avgörande för alla verksamheter, inte minst i samband med digitalisering: att skapa och vidmakthålla gemensam förståelse över tid.