Informationsarkitektens mörka materia

Det handlar om all den information som inte finns i databaser. En stor mängd av den information som hanteras i en organisation finns inte strukturerad i tabeller, databaser eller liknande. Oftast är det frågan om text men kan också vara bild, ljud, video eller kombinationer av format. Det vill säga allt sådant som brukar kallas ”ostrukturerad” information. Hur kan vi identifiera och hantera detta?
Informationsarkitekturens mörka materia
Om vi på allvar vill stödja informationshanteringen i en verksamhet så måste vi börja intressera oss för all den så kallade ”ostrukturerade” information som finns i organisationen. Den är en mycket stor mängd av den totala informationsmängden, men hittills har inte många intresserat sig för detta. Det är på så sätt att likna vid en mörk materia för oss. Den finns där och den är viktig, men vi vet inte mycket om den och vi låtsas att den inte finns.
Det vi kallar ”ostrukturerad” information är egentligen inte alls ostrukturerad
För att kunna hantera något så behöver vi först identifiera vad det är vi ska hantera. Vilka enheter pratar vi om? Ett fruktbart sätt att se på informationen i en organisation är att se den som olika dokument. Ett dokument i denna mening är en artefakt som bär information av något slag, och som vi väljer att se som en sammanhållen enhet. Det är naturligt att varje organisation har mycket information i form av sådana enheter av information. Avtal, polices, produktblad, villkorstexter, ritningar, modeller, powerpointpresentationer, bilder, böcker, videoinspelningar, blogginlägg, bilder, reklam- och informationsmaterial, scheman, utbildningsmaterial, broschyrer, specifikationer, offerter, fakturor, rapporter, prognoser, epostmeddelanden, med flera. Jag väljer här att kalla alla dessa saker för dokument.
Det viktiga är att ett sådant dokument omfattar det man vill se och hantera det som en helhet, det vill säga att varje del av innehållet i dokumentet får en mening av det sammanhang som dokumentet utgör. Ett dokument är alltså inte en godtycklig paketering av data eller information. Lika lite som en roman bara är ett antal ord, eller en bild endast ett antal pixlar. Helheten är mer än summan av delarna. Detta är mycket viktigt, och något som ofta förbises av alla oss som är vana vid de uppstyckade data som finns i databaser.
Ofta har man kallat den information som finns i dokument av olika slag för ostrukturerade data för att skilja den från det som finns i databaser, som man då menar är strukturerad. Jag hävdar att detta är fel. Data eller information i ett dokument är nästan alltid extremt strukturerad. Du kan ju inte skaka om innehållet så att alla bokstäver, meningar, stycken blandas utan att dess mening går förlorad.
Informationen i dokument är alltså också strukturerad, fast på ett helt annat sätt än informationen i en databas.
Men informationen i en databas kan faktisk också ses som dokument. Där finns kundposter, avtal, offerter, produkter. Varje sådan post är vanligen mer än en post i en tabell. En faktura till exempel är mer än den databaspost som representerar fakturahuvudet, den inkluderar även fakturaradernas databasposter. Dokument är således att se som en betydelsebärande helhet av information, oavsett hur det lagras.
Man kan dock tänka sig alternativa beteckningar. Ibland kallar man detta för informationsobjekt, de enheter av information som man kan betrakta som meningsfulla enheter. Jag använder här termen ”dokument” för att jag tycker att den är mer konkret. När man hanterar innehåll på webbplatser kallas innehållet för ”content”, och kanske kan man då kalla dessa enheter av information man hanterar för content objects (innehållsobjekt)?
I vilket fall som helst, vad vi än kallar det för, det jag väljer att kalla för dokument, är det viktiga objekten för all informationshantering i våra verksamheter.
Vem hanterar dokument?
Förr fanns alla dokument i fysisk form på papper. Numera lagras och distribueras det mesta digitalt. Men fortfarande har dock försäkringsbolag och myndigheter kvar hyllkilometrar av papper, vilka är arkiverade i bergtunnlar. Men övergången till digital hantering betyder inte att dokumenthantering har försvunnit. Tvärtom! Mängden av dokument har bara ökat och behovet av hantering är minst lika stor som förut. Skillnaden är bara att de flesta nya dokument är digitalt lagrade.
Det finns yrkesgrupper som traditionellt har administrerat denna flod av dokument. Det finns bibliotekarier och det finns arkivarier. Dessa har alltid funnits. Sedan har det tillkommit de som arbetar med innehållet på stora webbplatser. Det de gör brukar kallas för Information Architecture då det handlar om strukturen, och Content Management då det handlar om själva innehållet. Några av dessa har intresserat sig för det bakomliggande, det vill säga inte bara det innehåll som finns på en viss webbplats utan för mer eller mindre allt material som innehåller information i en verksamhet. Det brukar då ibland benämnas Enterprise Information Management eller Enterprise Content Management.
Var kommer vi informationsarkitekter in?
Vi som tillhör den stam av informationsarkitekter som ursprungligen kommer från databasdesign och datamodellering har i ringa utsträckning brytt oss om dokumenthantering. De som också kallar sig för informationsarkitekter men som kommer från, och ingår i, skaran av UX:are (User Experience- specialister) har mest intresserat sig för strukturen på en webbsida eller liknande. Men som sagt; vissa av dessa har börjat intressera sig för en verksamhets hela dokumentflora och kallar då området för Enterprise Information Management. Fast de kallar det ofta inte för dokument utan det mer neutrala ”content”.
Men jag tycker att det är dags att ändra på detta. Låt oss se informationsarkitekturområdet i hela dess bredd, att vi intresserar oss för de strukturer som behövs för att hantera all slags information i en verksamhet, oberoende av struktur eller media.
Det är därför jag skriver denna artikel om hur vi kan hantera dokument.
Olika perspektiv på dokumenthanteringen
Om man studerar området dokumenthantering så ser man snart att det finns olika perspektiv. Olika yrkesgrupper har haft olika roller vad beträffar hanteringen av dokument och har därmed utvecklat sin egen apparat av begrepp och praxis.
Jag tror att de vanligaste perspektiven är följande:
- Informationsanvändning och användbarhet
Hur blir de strukturer av innehåll vi bygger i olika sammanhang, till exempel på webbplatser, användbara för de som behöver informationen.
- Informationssökning
Hur kan användare hitta och komma åt de dokument de behöver (index, söksystem, taggar, klassificering).
- Dokumenthantering
Hur kan vi hantera dokumenten under hela deras livscykel (versioner, varianter, mallar).
- Systemperspektiv
Vilka applikationer hantera dokumenten och hur är hanteringen integrerad (HR-system, ekonomisystem, workflow-system, dedikerade informationslager, arkivsystem, Content Management-system, med flera). Här fokuserar man på hur dokumenten flödar genom hela it-miljön.
- Förmågeperspektiv
Hur de olika dokumentflödena går mellan olika parter, interna och externa.
- Processperspektiv
Hur en viss process hanterar de dokument som den är beroende av eller producerar.
- Organisation av kunskap
Hur kan vi hantera dokument med tanke på organisation av den kunskap som de bär.
- Informationssäkerhet
Hur kan vi klassa dokument för krav på tillgänglighet, riktighet och konfidentialitet och hur kan vi se till att hantera de kraven (säkerhetsklassning av information).
Men var kommer då vi informationsarkitekter in? Informationsarkitektur handlar ju om att göra modeller och beskrivningar, och att använda dessa för att stödja olika aspekter av informationshanteringen. Jag menar att vi informationsarkitekter behöver stödja alla dessa perspektiv. Det vi bidrar med är att skapa modeller och beskrivningar för de strukturer som behövs för att hantera dokument och att använda dessa modeller och beskrivningar för att guida hela organisationen med detta.
Stödförmågor för hantering av dokument
Varje organisation behöver generella förmågor eller funktioner för att hantera dokument och informationsobjekt av olika slag. De är stödförmågor eftersom de är till stöd för andra förmågor. De tillhandahåller generella verktyg och funktioner.
Denna typ av verksamhetsförmågor brukar ofta ses som tekniska förmågor eftersom varje funktion ofta kräver en viss typ av it-stöd. Men jag menar att det är fel. Som alltid handlar förmågor om mycket mer än teknik, ty varje förmåga kräver förutom it-stöd även processer, rutiner, regler, kompetens, strategi, ledning med mera. En förmåga är alltid en egen liten specialiserad verksamhet med allt vad det innebär. Tekniken som behövs är en integrerad del av en förmåga.
Dessa förmågor är att betrakta som stödförmågor eftersom ingen av dessa är någon central förmåga hos en verksamhet, det vill säga det som är specifikt för en verksamhet. En stödförmåga är stöd till en eller vanligen flera av de centrala förmågorna. Man kan säga att stödförmågorna för dokumenthantering tillsammans utgör den infrastruktur som behövs för hantering av dokument och andra sammanhållna informationsobjekt. Även termen infrastruktur kopplas ofta ihop med teknik men det är förstås i detta fall mycket mera. Infrastruktur är helt enkelt den struktur som ligger under de andra i arkitekturen, det vill säga som de andra är beroende av.
Vilka är då alla dessa stödförmågor för hantering av dokument som vi som informationsarkitekter ska stödja? Här följer en genomgång av de förmågor, varje verksamhet behöver i någon form, som har med hantering av dokument att göra.
- Stöd för samarbete
Handlar om att utbyta information i form av meddelanden som alla kan ses som dokument av olika slag. De kan delas in i följande stödförmågor:
– Stöd för kommunikation, intern och extern
E-post, text- och röstmeddelanden med mera.
– Stöd för möteshantering
Mötesbokning, rumsbokning, videomöten med mera
– Stöd för hantering av sociala nätverk och delande av kunskap
Bloggar, wikis, samarbetsytor, diskussionsforum etcetera.
- Stöd för sökning och åtkomst till dokument
Processande av sökfrågor, hantering av sökresultat, sökanalys och rapportering, hantering av sökindex.
- Stöd för kunskaps- och informationshantering
- Stöd för skapande av informationsobjekt
Dokumentscanning, OCR-scanning, stöd för dokumentskapande, versionshantering, hantering av formulär med mera. - Dokumenthantering
Dokumenthanteringssystem, ytor för olika team, nätverksdrives etcetera. - Organisering av dokument
Kataloger, klassificering av dokument, taggning och indexering av dokument. - Informationssäkerhet
Säkerhetsklassificering, autentisering, kryptering, rättighetshantering. - Livscykelhantering
Arkivhantering, fysisk och digital dokumentförstöring etcetera.
- Stöd för skapande av informationsobjekt
- Stöd för hantering av semantik
- Stöd för vokabulärer
Ordlistor, ämnesscheman, klassificeringsscheman, nyckelordlistor etcetera. - Stöd för representation och översättning av information
Resurser för tolkning och översättning, mallar, scheman etcetera. - Hantering av dokumentmetadata
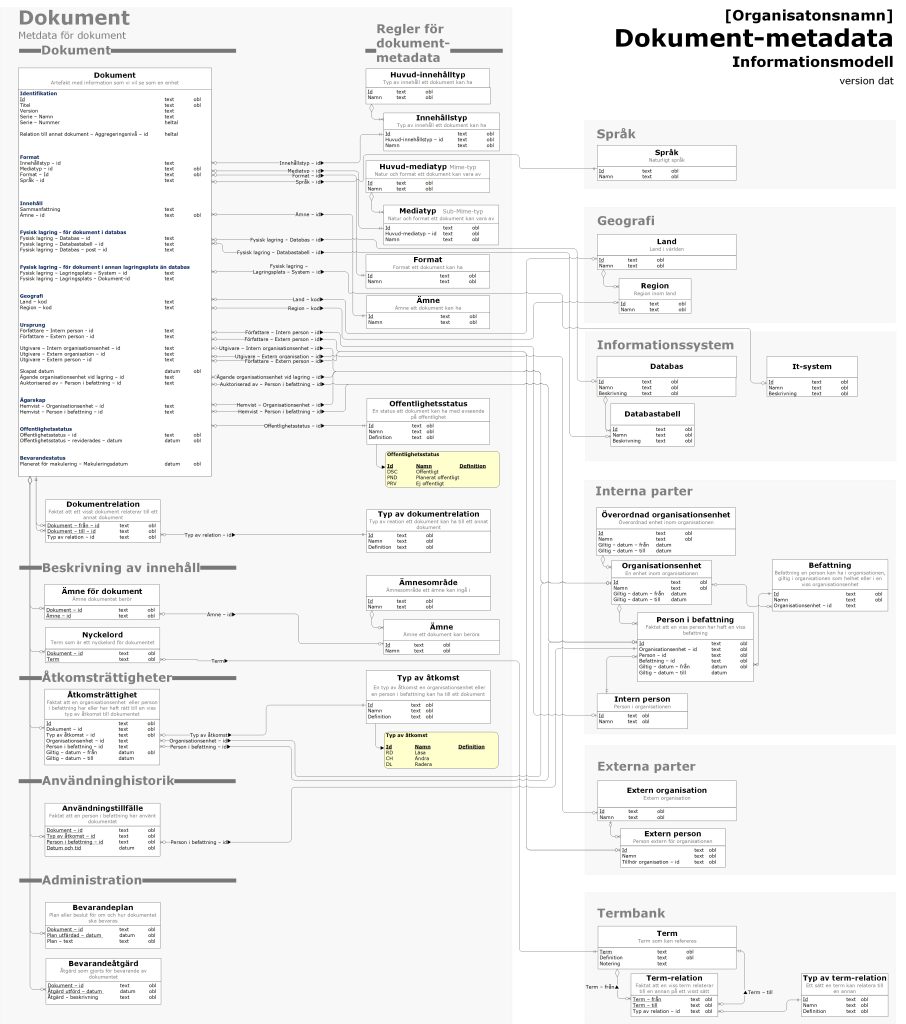
Metadatamodeller, metadatalager. Metadata är av central betydelse för dokumenthanteringen. Därför handlar resten av artikeln om detta.
- Stöd för vokabulärer
Alla verksamheter oavsett storlek behöver i princip dessa förmågor, men de är ofta i mindre organisationer så enkla att man typiskt inte tänker på att de finns. Men de finns egentligen alltid där, i någon form. Ofta är de rudimentära och outvecklade. Kanske det räcker, men i många fall behöver vi stärka dessa.
Dokumentmetadata
Hur behöver vi informationsarkitekter stödja dessa förmågor? En central aspekt är att ta fram en gemensam modell för dokumentmetadata. För att ha någon typ av ordning i floden av dokument behöver vi på något sätt tagga dessa med egenskaper. Detta för att kunna sortera, söka, strukturera och på andra sätt hantera dokumenten. Men då måste vi bestämma och definiera egenskaperna i fråga. Det kallas ofta för dokumentmetadata. Metadata definieras ”data som beskriver data”, i detta fall, data som beskriver dokument. Det handlar ju om data om dokumentet i fråga, till skillnad mot det data som finns i dokumentet.
Vi kan dela in dokumentmetadata i två kategorier. Generella metadata (Core Metadata) och Utökade metadata (Extended Metadata).
Generell dokumentmetadata är metadata som stödjer informationshantering tvärs över hela organisationen och som därmed måste finnas för alla dokument oavsett typ. Utökad dokumentmetadata är den metadata som varierar beroende på typ av dokument. Ofta beror det på de speciella behov en viss verksamhetsförmåga har för att kunna hantera sina speciella dokument.
Vad behöver vi metadata till?
Man kan säga att dokumentmetadata har fyra syften och behövs för att:
- identifiera olika dokument och skilja dem åt.
- stödja att vi kan söka och leta bland dokument för att hitta data och information.
- säkerställa tillbörlig åtkomst och användning av data och information i dokument.
- stödja hantering och administration av dokument över dess livscykel.
Attribut för generella dokumentmetadata
För vart och ett av de syften som nämndes ovan kan man tänka sig ett antal metadata-attribut som behövs för att stödja just det syftet. Exakt vilka generella metadata-attribut man väljer att ha beror på organisationens art och behov och måste väljas av organisationen själv.
Nedan följer exempel på attribut för generella metadata för dokument som en organisation kan välja att ha. Dessa är sorterade efter vilket syfte de stödjer.
- Syfte: Identifiera dokument och skilja dokument åt
- Författare (Author)
Möjliga värden kan ha en kontrollerad källa, en lista med namn. Den kan eventuellt stödjas av en lista med synonymer för olika skrivsätt. Exempel: ”Peter Tallungs”, ”P. Tallungs”, ”P.T:”. I det fall möjliga författare är samma som alla medarbetare så kan listan med möjliga värden hanteras av organisationens masterdata-funktion. - Titel (Title)
Har regler för antal tecken, men inte någon kontrollerad källa för möjliga titlar. - Datum (Date)
Datum då dokumentet skapades, eller blev färdigt. - Format (Format)
Säger vilken form av data dokumentet innehåller och hur det är kodat.
Bör ha en kontrollerad källa för möjliga värden.
MIME är en allmänt förekommande standard som ofta används. - Utgivare (Publisher)
- Språk (Language)
- Version (Version)
- Serie: Namn och nummer (Series name and Number)
- Innehållstyp (Content Type)
Kan ha en kontrollerad källa för möjliga värden att välja från och bör stödjas av en hierarkisk klassificeringsstruktur. Denna struktur är typiskt bred och grund.
- Författare (Author)
- Syfte: Söka dokument, och bläddra bland dokument
- Land (Country)
- Region (Region)
- Sammanfattning (Abstract/Summary)
- Nyckelord (Keywords)
Kan ha en kontrollerad källa för möjliga värden som då bör hämtas från en organisationsgemensam ordbok, lämpligen en så kallad thesaurus. En sådan innehåller de termer som bör användas samt hur de relaterar till varandra inom organisationens domän.
Observera att nyckelord inte är samma som ämne. - Ämne (Topic/Subject)
Kan ha en kontrollerad källa för möjliga värden som då bör stödjas av en hierarkisk klassificeringsstruktur. Denna struktur är typiskt bred och grund. - Organisationsenhet (Business Function)
Anger vilken organisationsenhet som ägde informationsobjektet då det lagrades.
Bör ha en kontrollerad källa för möjliga värden alla organisationsenheter som organisationen har eller har haft historiskt. Uppsättningen av möjliga värden bör stödjas av en hierarkisk struktur som visar organisationens uppbyggnad både idag och historiskt. Det betyder att strukturen måste underhållas och uppdateras när organisationen ändras, men också att äldre strukturer måste bevaras. Strukturen är typiskt smal och djup.
- Syfte: Åtkomst och användning
- Auktoriserad av (Authorized By)
- Åtkomsträttigheter (Access Rights)
Vem som har rätt till, eller vilka rättigheter som krävs för att komma åt, ändra eller radera dokumentet. - Hemvist (Location)
Vilken organisationsenhet eller befattning som har ansvar för dokumentet. - Användningshistorik (Use History)
Vem som har använt dokumentet och när. - Offentlighetsstatus (Disclosure status)
Om dokumentet är offentliggjort för tillfället, är avsett att offentlighetgöras i framtiden eller inte är avsett att offentliggöras.
Möjliga värden är en flat lista med värden definierade av någon auktoritet i organisationen. Alla system inom organisationen bör ha samma uppsättning möjliga värden. - Offentlighetsstatus – reviderades – datum (Disclosure Review Date)
Datum då offentlighetsstatus för dokumentet bestämdes eller ändrades.
- Syfte: Hantering och administration
- Post-id (Record Identifier)
Id för dokument som lagras som poster i en databas. - Makuleringsdatum (Disposal Status)
Datum då dokumentet ska makuleras. - Hanteringshistorik (Management History)
Datum och åtgärd som har gjorts för hantering av dokumentet. - Bevarandeplan (Retention Schedule/Mandate)
Plan eller beslut för hur dokumentet ska bevaras. - Bevarandehistoria (Preservation History)
Datum och åtgärd som har gjorts för bevarande av dokumentet. - Aggregeringsnivå (Aggregation Level)
I det fall dokumentet ingår i en hierarki av dokument, nivån i hierarkin detta dokument befinner sig i. - Relation (Relation)
Namn på den hierarki detta dokument ingår i samt vilket närmast överliggande dokument detta dokument är en del av.
- Post-id (Record Identifier)
Exempel på utökade dokumentmetadata-attribut
Som sagt behöver specifika typer av dokument även specifika metadata-attribut. Projektdokument kan behöva attribut för projektnamn och typ av projektdokument. Epostmeddelande som ska sparas som allmänt tillgängliga behöver sändare, mottagare och så vidare.
Hur tar jag fram en metadatamodell för vår organisation?
Vilka metadata-attribut ska vi ha för organisationens dokument och vilka ska reglerna vara för varje attribut? Detta behöver varje organisation komma fram till. Det finns ingen ”one size that fits all”. Bästa sättet är att gå igenom de befintliga system som skapar eller hanterar dokument samt ett representativt urval av dokument av olika slag, och hur de behöver hanteras, för att därifrån komma fram till vilka metadata-attribut som passar vår verksamhet.
Sedan är det lämpligt att ta fram en informationsmodell för organisationens gemensamma önskade dokumentmetadata. Modellen uttrycker de krav vi ställer på alla verksamhetsförmågor (och därmed applikationer) som ska skapa eller uppdatera dokument, beträffande vilken metadata de ska kunna tagga dokument med.
Det finns några fällor att se upp med här. En fälla är att tro att man bara utan vidare kan anamma en populär standard, som till exempel Dublin Core. Dublin Core är utformad för att underlätta åtkomst till offentligt publicerade dokument, vilket bara är en del av det vi behöver kunna lösa. Dublin Core säger till exempel inget om de metadata som behövs för livscykelhantering. Man kan absolut använda olika publicerade standarder. Men då bör man först analysera, och förstå sin egen organisations behov. Först därefter kan man se vilka publicerade standarder som passar.
En annan fälla är att anamma en standard för hur man kodar metadata, och därmed tro att man har löst problemet. En kodningsstandard för metadata säger inget om vilken metadata man ska ha bara hur den kan paketeras och utbytas.
Hur kan vi hantera dokumentmetadata?
Hur, var och när ska dokument tilldelas sina metadata och hur ska den sedan göras tillgänglig för de som behöver den? Om vi hanterade organisationens alla dokument i ett och samma system vore det enkelt. Men det är inte realistiskt. Monolitiska lösningar är aldrig något hållbart, och i detta fall mer orealistisk än någonsin. Med tanke på att dokument skapas i så många olika former och i så många olika sammanhang.
Vad vi behöver är ett centralt register för dokument, där de olika applikationerna som skapar och hanterar dokument av olika slag kan registrera dokumenten. Det innebär att själva dokumenten ligger kvar i sina applikationer men en metadatapost för dokumentet registreras centralt. Det blir alltså som ett register i ett bibliotek. Vi har då fått en distribuerad och därmed mer flexibel och realistisk arkitektur. Det enda vi verkligen behöver hantera gemensamt hanterar vi gemensamt, det vill säga metadata.
Hur skapar vi metadata?
Varje gång ett dokument som har någon form av allmänt intresse skapas, ändras eller hanteras behöver metadata om dokumentet skapas eller hanteras. Hur ska det gå till? En del registrerar vi redan idag när vi skapar något, eller bör göra i varje fall. Som titel, datum med mera. En del behöver vi bygga möjligheter för att registrera manuellt. Annat kan vi kanske automatisera, mer eller mindre. Det finns semantiska tekniker av olika slag med regler för att automatiskt skapa metadata utifrån innehållet i ett dokument. Men det är nog orealistiskt att vi idag eller inom en nära framtid ska kunna luta oss mot sådana, speciellt som vi idag i allmänhet inte ens har börjat tänka i termer av hantering av dokument och vilken metadata som skulle behövas och till vad.
Utkast till en informationsmodell för dokumentmetadata
För att illustrera hur detta kan se ut har jag tagit fram ett utkast till en informationsmodell för dokumentmetadata i en organisation. Se bild sist i denna artikel. Observera att den endast täcker generella dokumentmetadata.
Hur gör ni i er organisation?
Hur hanterar ni dokument? Hur stödjer du som informationsarkitekt dokumenthanteringen? Kanske har du synpunkter som jag har missat här. Jag vill gärna höra dina erfarenheter.
/Peter Tallungs, IRM