Kategorisering av data för Data Management

Olika kategorier av data behöver hanteras på olika sätt. För att bygga upp Data Management behöver vi förstå hur olika slags data skiljer sig från varandra.
/Peter Tallungs, IRM 2023-12-14
Tillägg till tidigare artikel
För nästan tre år sedan skrev jag en artikel om hur man för Data Management kan dela in data i olika kategorier med avseende på egenskaper. Skillnaderna gör att kategorierna behöver hanteras olika. Artikeln heter ”Det är skillnad på data och data” och publicerades den 25:e februari 2021.
Jag missade något då som jag nu vill korrigera. Jag identifierade då först de två kategorierna Masterdata och Globala referensdata. Sedan behövdes det ett namn för data som representerar sådant som händer i verksamheten och ofta har någon utsträckning över tiden, som ordrar, offerter och ärenden. Jag kallade dessa för ”Händelsedata”.
Vad jag missade var att särskilt urskilja den kategori av data som representerar momentana händelser. Till exempel att en köporder avslutas, att ett ärende stängs, en leverans skickas etcetera. Det är visserligen också händelser men vi behöver skilja på sådant som händer med en utsträckning över tiden och momentana händelser. Jag blev varse om detta strax efter jag skrev artikeln, och allt sedan dess har jag tänkt att redovisa denna mera fullständiga kategorisering i en ny artikel. Av någon anledning hr det inte blivit av. Men nu kommer den.
Nytt försök
Jag föreslår att vi kallar sådant som är händelser med en utsträckning över tiden, och alltså har en livscykel i någon form, för ”transaktioner”. Och sådant som äger rum momentant och därmed aldrig kan förändras efter de kommit till, för ”händelser”. Det stämmer bäst överens med allmänt språkbruk och det stämmer också med vad som benämns som händelser inom till exempel händelsedriven it-arkitektur.
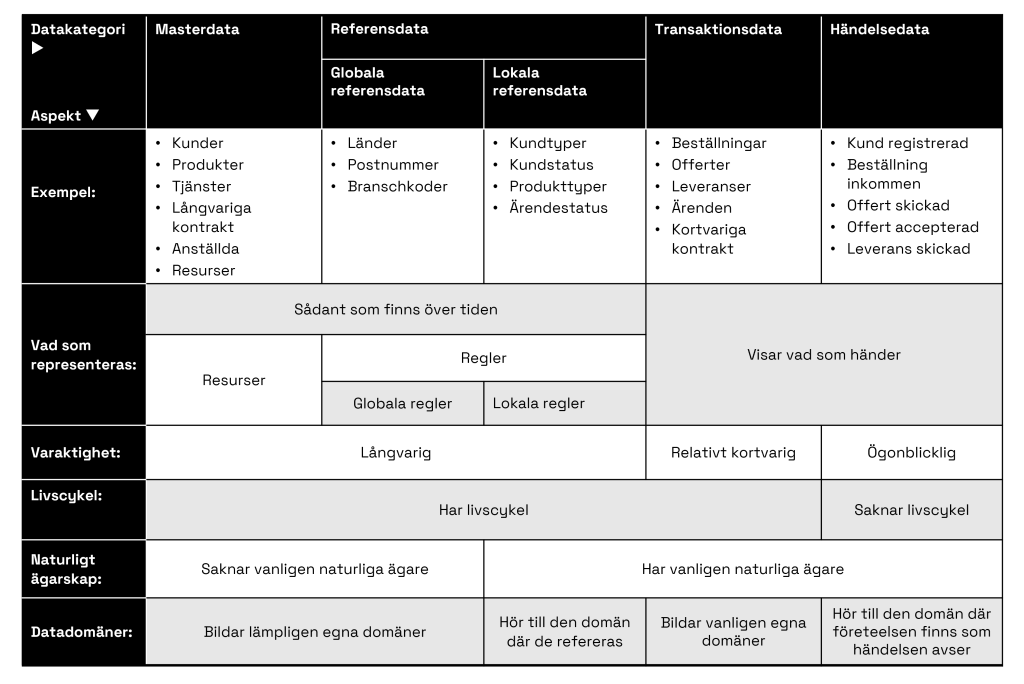
Resultatet blir då följande kategorisering. Kategorierna skiljer sig åt i olika aspekter, vilket redovisas som rader i matrisen nedan.
Förklaring till aspekterna
I det följande förklaras varje aspekt och varför varje datakategori skiljer ut sig från de andra kategorierna i denna aspekt.
Aspekt: Vad som representeras
Masterdata beskriver centrala företeelser som lever över tid och refereras från många håll. Vanliga exempel är kunder och produkter eller tjänster, men kan även vara andra saker.
Referensdata är värdeförråd för attribut, det vill säga att de utgör regler för vilka värden ett (eller flera) attribut kan anta. Som kategoriseringar av olika slag. De existerar också över tid. Då det gäller referensdata vill jag skilja på lokala och globala referensdata, eftersom de styr hur de kan bilda ämnesområden och därmed datadomäner.
Lokala referensdata refereras bara av entiteter inom ett visst ämnesområde medan globala referensdata refereras från flera ämnesområden. Lokala referensdata hör då naturligt hemma i de ämnesområde där de refereras. De är helt enkelt en del av regelplanet för det ämnesområdet. Exempel: Posterna i entiteten Kundtyp säger vilka typer en kund kan vara av. Men globala referensdata som till exempel länder i världen refereras ofta från många olika ämnesområden, och behöver därmed bilda egna ämnesområden, kanske i detta fall tillsammans med andra geografiska indelningar i ämnesområdet ”Geografi”.
Aspekt: Varaktighet
Varaktighet handlar om hur länge företeelsen som dataposten representerar lever. Märk att det inte säger hur länge dataposten ska sparas, vilket inte är en egenskap hos själva företeelsen som dataposten representerar utan en egenskap hos dataposten i sig, det vill säga en typ av metadata.
Masterdata och referensdata står för företeelser som är mer bestående än det som de övriga kategorierna representerar.
Transaktioner har en utsträckning i tid men relativt kort i förhållande till det som representeras av masterdata.
Kund- och leverantörsavtal är oftast att betrakta som transaktioner. Men i de fall de är kontrakt som sträcker sig över år och vi ser dessa som mer eller mindre beständiga tillgångar är dessas data att se som masterdata.
Händelser har ingen utsträckning i tid utan är över så fort de händer.
Aspekt: Livscykel
Om en företeelse har en livscykel så blir den till vid ett tillfälle och slutar att finnas vid ett annat tillfälle. Det finns då alltså livscykelhändelser liksom tillstånd. För en kund kan det vara att den först blir prospekt, senare kund och sen efter en tid tidigare kund. Masterdata och transaktionsdata representerar företeelser som alltid har livscykler i någon form. Referensdata har egentligen också livscykler, men det är inte alltid vi behöver hantera detta, speciellt inte i operativa sammanhang där vi mera är intresserade av nuläget än av historien. Över tid, som i analyssammanhang, behöver vi mer ofta veta när till exempel en viss kundkategori ersattes av två andra.
Händelser lever inte över tid och har därmed ingen livscykel och inga tillstånd.
Dock kan data som beskriver en händelse ha tillstånd och händelser, som till exempel när en viss datapost lästes in. Men då är vi på återigen på metadatanivå, vilket är något annat. Den händelsen är något som hänt i ett it-system och inte ute i den verklighet som dataposten representerar.
Aspekt: Naturligt ägarskap
Masterdata saknar nästan alltid naturliga ägare i våra organisationer. Alla är beroende av kunddata och olika delar av verksamheten har olika krav på kunddata, men vanligt är att ingen vill och kan ta det gemensamma ansvaret. Det är en av anledningarna till att man pekar ut masterdatahantering som ett särskilt område då man bygger upp Data Management. Situationen är densamma för globala referensdata, fast där är uppgiften vanligen enklare. Dock inte alltid. Ibland kan datamängden för referensdata vara riktigt omfattande och samtidigt volatil.
Vi behöver därför skapa särskilda förmågor för att hantera masterdata, liksom globala referensdata, vilket innebär att de blir en eller flera särskilda verksamhetsfunktioner med allt vad detta innebär; med organisation, arbetssätt, it-applikationer, tjänster etcetera.
Övriga datakategorier har nästan alltid naturliga hemvister i den organisation som redan finns på plats.
Aspekt: Datadomäner
Lokala referensdata refereras lokalt vilket innebär att de naturligt hör till den domän där de refereras. Händelser sker alltid med någon form av företeelse, ofta något som representeras av masterdata eller transaktionsdata. Därmed hör händelsedata naturligt till dessas domäner.
Masterdata behöver bilda egna domäner, eftersom de används i många olika sammanhang. Detta gäller vanligen också för transaktionsdata.
Beroendeobjekt delar kategori med sina föräldrar
Det finns alltid många beroendeobjekt, det vill säga en entitet vars förekomster är existentiellt knutna till förekomster hos en annan entitet. Som att fakturarad hör ihop med sin faktura. Fakturaraden kan inte existera utan sin faktura och den kan aldrig byta faktura. Detta existentiella beroende har vi också mellan en kontopost och dess konto liksom mellan en lagerpost och det lager den avser.
Ett sådant så kallat beroendeobjekt har en typ av relation till sitt förälderobjekt som kallas sammansättning eller composition i UML. Det betyder att det är existentiellt hopkopplat med sin förälder. Det har därmed ingen egen kategori utan delar kategori med sin förälder. Fakturarader är alltså transaktionsdata eftersom fakturor är transaktionsdata.
Men vad gör vi med konton?
Jag tycker att konton av olika slag, som finansiella konton eller lagerkonton är svårkategoriserade. På sätt och vis kan man se konton som lokal referensdata. Som en kategorisering, en taggning av en kontopost, och en kontopost är en händelse eftersom det är något som händer momentant.
Men på samma gång är konton någon form av resurser, och alltså besläktade med masterdata. Kanske att vi behöver ytterligare en kategori, mitt emellan masterdata och referensdata? Kanske vi kan se masterdata som ett slags globala resursdata och konton som lokala resursdata? Det vill säga att båda håller data om resurser som vi behöver hålla reda på. Och att skillnaden är att masterdata är sådant som används mer brett, det vill säga refereras från många olika håll i verksamheten medan sådant som konton har en mer naturlig hemvist och därmed kan ses som lokala resursdata? Det är sådant jag funderar på? Kanske att du som läser detta har en tanke där? Kanske vi kan hjälpas åt att få det att klarna.
Andra kategoriseringar
Det finns ingen klassificering som täcker alla syften. Det sätt att kategorisera data som jag beskriver här har syftet att stödja uppbyggnaden och organisationen av datahantering. Vi behöver också flera andra sätt att klassificera data till exempel med avseende på lagringskrav, ursprung och säkerhetskrav. Det är inte alternativa klassificeringar utan kompletterande. Men det är en annan femma.
Nu är det din tur
Jag är övertygad om att inte heller det slutgiltiga svaret, utan att vi kan lära oss mer. Vad har jag missat?