”Data” eller ”information”
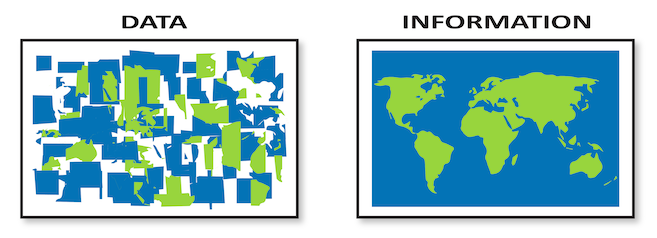
Vad är skillnaden? Jag tvekar ofta om jag ska benämna något som ”data” eller ”information”. Är det data eller är det information? Är detta som jag tar fram en datamodell eller en informationsmodell?
/Peter Tallungs 2021-04-01
I Sverige kallar vi en konceptuell modell ofta för informationsmodell och en logisk eller fysisk modell ofta för datamodell. Men i USA talar man vanligen bara om ”Data Models” oavsett om de är konceptuella, logiska eller fysiska. Hur kan vi se på det?
Den påstådda teoretiska skillnaden
Alla som definierat begreppen data och information verkar vara överens om att data är råa uppgifter utan sammanhang och tolkning. Tänk att du tittar på en massa siffror men inte vet, eller bryr dig om, vad de står för. Vidare är man överens om att information är data som har ett sammanhang och tolkning.
Hur uppkom distinktionen?
Det kan vara intressant att veta hur distinktionen mellan data och information kom till. Inom system- och informationsvetenskap skedde detta i skiftet mellan 70- och 80-tal. Det var när man strävade efter att få sina områden att bli respekterade som strategiska management-discipliner. Man ville få företagsledningar att se data som en strategisk tillgång och lanserade därför en tänkt process med en transformering och filtrering från data via information till kunskap och ibland till och med ända till visdom.
Synsättet har genom åren blivit kritiserat som en alldeles för mekanisk och förenklad syn på kunskapsprocessen i en organisation. Visst spelar data och information en roll i kunskapsskapandet men sammanhangen är mycket mer dubbelriktade och sammansatta.
Se till exempel David Weinbergers artikel ”The Problem with the Data-Information-Knowledge-Wisdom hierarchy” och Patrick Lambs bloggartikel “From Data, with Love”.
Det var i sammanhanget som är beskrivet ovan som en del började kalla datamodeller för informationsmodeller och Data Management för Information Management. Förmodligen för att få företagsledningars uppmärksamhet. Av någon anledning slog det språkbruket igenom i Sverige men inte i USA.
Som så ofta handlade det alltså mer om politik och revirpinkande än om någon verklig insikt.
Idag, ett halvsekel senare, kan man tro att ordens statusordning har kastats om. ”Data” har fått en ny laddning. Trenduttryck som ”Data is the new oil”, ”Data driven enterprise”, ”Data Science” och “Chief Data Officer” vittnar om att data inte längre ses som någon tråkig mekanisk infrastruktur.
Detta var en liten historisk bakgrund. Låt oss återgå till distinktionen mellan data och information.
Vad är sammanhang och tolkning?
Om vi för diskussionens skull godtar att data blir till information vid den tidpunkt då den får ett sammanhang och en tolkning. När inträffar då denna punkt i processen? Problemet kommer då vi ska bestämma vad vi egentligen menar med sammanhang och tolkning. Vad är tolkning och sammanhang? När sker tolkningen av data? När sätts data i sitt sammanhang? Dessa frågor kan först verka ha enkla svar men blir vid en närmare betraktelse meningslösa.
Redan när data samlas in görs det i ett sammanhang som är känt och ges direkt en tolkning genom hur den hanteras.
Låt mig ta ett exempel. En givare av något slag ger ett mått på något, säg värdet ”23”. Någonstans där värdet från givaren registreras bör det nödvändigtvis finnas inbyggd kunskap om sammanhang och mening med mätningen. Man vet kanske att det är en temperaturgivare och att det är grader Celsius. Man vet var givaren sitter och därmed inte bara att det är lufttemperatur utan också på vilket ställe lufttemperaturen är registrerad. Utöver detta vet man också redan vid registreringen vilken tidpunkt värdet registrerades. Allt detta är mening och sammanhang för datapunkten och registreras alltså med en gång, bara genom vad det är för slags sensor och var den sitter. Om man ska vara strikt kan man hävda att det aldrig är frågan om rådata i egentlig mening. Om vi kan vara överens om detta så är det alltid fråga om information, ända från då den registreras.
Så, en sådan distinktion vi tidigare gjorde blir meningslös. I så fall, med det resonemanget, finns aldrig data, bara information.
Vad det beträffar de modeller vi gör så blir det väl då alltid frågan om informationsmodeller. Ty där bryr vi oss alltid om meningen med de data vi hanterar.
Ett kontinuum snarare än en gräns
Låt oss pröva ett annat synsätt. Kanske vi kan se det som att data blir till information först när någon människa har tagit hand om de insamlade data, gett det en ännu mer utarbetad tolkning. Om vi tänker oss att man samlat in lufttemperaturer under en tid och jämför med andra år och därmed kan säga att det varit en ovanligt varm marsmånad i år. Är det först då det blir information? I så fall hanterar vi vanligen inte alls information i våra informationsmodeller. Informationen uppstår först i de analyser och slutsatser man drar efter ett mänskligt bearbetande, och hanteras typiskt som text i en rapport av något slag.
Det är tydligt att vi har att göra med ett kontinuum där övergången från data till information är helt och hållet flyttbar. Den rör sig beroende på vad man lägger i begreppen ”sammanhang” och ”mening”.
Data och information på samma gång?
Det är möjligt att se det hela på ett annat sätt. Låt oss lämna resonemanget med en tänkt process, det vill säga föreställningen att data övergår till att bli information vid någon bestämd punkt. Vi kan i stället se det så att samma insamlade siffror är både data och information samtidigt beroende på vilka aspekter vi för tillfället fokuserar på. När vi pratar om megabytes eller megabits per sekund så bryr vi oss inte om vare sig mening eller sammanhang. Då pratar vi om lagring eller transport av data, utan att bry oss om vad de står för. Men när vi verkligen vill titta på och förstå vad dessa data betyder ser vi det som information.
Det är det synsättet jag har fastnat för. Det är helt analogt med andra mänskliga områden. Om jag kör lastbil så kanske jag bara bryr mig om hur många ton och kubikmeter gods jag har. Men för mottagaren är det inte bara gods utan angivna mängder av specifika varor.
Några siffror är inte antingen data eller information utan både och, beroende på vilket perspektiv jag har för stunden. Distinktionen är ingen inneboende egenskap hos uppgifterna utan skillnaden ligger i betraktarens öga.
Problem med begreppet ”information”
Ett annat problem med termen ”information” är att den kan leda fel. Begreppet information leder närmast tankarna till sådant som ostrukturerad text och bild, det vill säga sådant som vi inte direkt hanterar i vårt skrå. Våra informationsmodeller visar ju endast sån information som är strukturerad som poster i en lista. Repeterbar abstraherad information, strukturerad för någon form av informationsprocessande. Termen ”data” ringar på ett bättre sätt in vad det handlar om än den alltför breda termen ”information”. I stora delar av världen kallas följaktligen det vi gör vanligen för ”Data Models”, ”Data Modeling”, ”Data Management” och så vidare.
”Information Management” står vanligen för en managementdisciplin, det vill säga hur man leder en verksamhet med information i centrum, alltså något helt annat.
Mer eller mindre synonymer?
Egentligen är väl distinktionen inte så viktig. Jag vill se termerna ”data” och ”information” som mer eller mindre synonyma. I varje fall i det sammanhang vi arbetar. Jag säger oftast ”data” eftersom jag anser att det leder tankarna lite mera rätt. Utom då det gäller modeller. Då säger jag vanligen ”informationsmodeller”. Inte så konsekvent språkbruk kanske, det är mest av gammal vana, och utan närmare eftertanke.
Vad säger du: data eller information? Gör du det som jag, av gammal vana eller har du reflekterat över vad orden egentligen står för?
/Peter Tallungs. IRM