Vi behöver rikare informationsmodeller

Om våra informationsmodeller ska vara riktigt användbara så behöver de kunna fånga och förmedla rejält med kunskap om verksamhetens företeelser, information och begrepp. Vad innebär det?
Rikare modeller
Jag menar att de informationsmodeller vi vanligen möter är tunna då det gäller vilken information och kunskap de bär. Jag brukar kalla dem för anorektiska. Ofta är de bara ett ER-diagram, det vill säga boxar för entiteter samt linjer för hur entiteterna relaterar till varandra. De är ämnade att ge oss en ytlig förståelse, men lämnar oss med fler frågor än svar.
Det är synd. Informationsmodeller måste bli mer mångsidigt användbara om de på allvar ska kunna stödja verksamhetens utveckling. De behöver bära mer information och kunskap om de företeelser verksamheten hanterar, information och data som representerar företeelserna, deras egenskaper och beteende samt språket för allt detta.
Våra informationsmodeller kan verkligen bli bättre, bara vi släpper några invanda föreställningar och slutar gå på i gamla spår. Jag hoppas att jag i min artikelserie om informationsarkitektur kunnat förmedla idéer om hur vi kan utveckla vår profession i allmänhet och i synnerhet mot det jag brukar kalla ”rikare” modeller.
Vad innebär då rikare modeller? Det betyder modeller som bär mer information och kunskap. Jag menar att det bör vara på följande sätt:
- En meningsfull övergripande struktur
- Bättre gestaltning, med både grafik och text
- Mer detaljer
- Fler dimensioner
Jag har skrivit mycket om detta tidigare i denna artikelserie, men nu vill jag särskilt fokusera på de två sista aspekterna; mer detaljer och flera dimensioner.
Mer detaljer
De flesta informationsmodeller jag möter är ER-diagram med bara boxar och linjer, det vill säga utan attribut och utan textuella beskrivningar. I bästa fall finns det definitioner av entiteterna. En sådan rudimentär modell kan vara en första början på en analys, men räcker inte i längden. Det behövs mycket djupare och bredare innehåll i modellen. Det vill säga alla realistiska scenarion för hur en arkitektfunktion behöver stödja en verksamhet. Det behövs följande:
- För entiteter: Namn, synonymer, definition, beskrivningar av olika slag samt regler.
- För attribut och relationer: Namn, synonymer, definition, beskrivningar av olika slag, logisk datatyp, giltiga värden samt regler.
- För värden i bestämda värdeförråd, det vill säga i det fall ett attribut har ett antal uppräknade möjliga värden): Kod, namn, definition, beskrivningar av olika slag samt regler.
Fler dimensioner
Den domän vi modellerar kan behöva struktureras på olika sätt utefter olika dimensioner, ofta flera dimensioner på samma gång. Det behöver vi kunna hantera i våra modeller.
Den kände grafikern och statistikern Edward Tufte har tagit fram ett antal principer för riktigt bra statistiska grafer. Jag har skrivit om detta i artikeln ”Vad vi kan lära oss av den bästa graf som någonsin ritats”. Jag menar att dessa principer är tillämpliga för oss också, vi som bland annat gör informationsmodeller och förmågekartor. En av hans principer är ”Visa multivariabel data.” Med det menar han att grafer blir riktigt intressanta först då de ställer tillsammans olika typer av information eller kunskap i en och samma graf.
Med flera dimensioner menas helt enkelt att man delar in samma domän på olika sätt och sammanför beskrivningarna i samma modell så att man kan se hur de olika dimensionerna samverkar.
Ett vardagligt exempel är följande: DN hade en gång på ett mittuppslag en karta över Stockholm där de med färger hade markerat hur folk i olika kvarter röstat i riksdagsvalet. Man sammanförde alltså geografisk information och partisympatier. De blev oerhört intressant. Vi satte upp kartan på väggen och diskuterade med barnen hur det kom sig att just den änden på gatan var röd då den andra var blå. Det blev nästan svårt att sluta titta på kartan då vi upptäckte nya samband hela tiden. Det är just det Tufte menar med värdet av att åskådliggöra multivariabel data i våra grafer.
Men vilka dimensioner kan man då tänka sig i en informationsmodell? Jag beskriver här några möjliga dimensioner som jag använt. Det får inte tolkas som att vi alltid måste strukturera modeller efter alla dessa dimensioner. Vissa dimensioner är alltid, mer eller mindre, relevanta medans andra kan behövas ibland. Här blandas stort och smått, vanligt och ovanligt.
- Ämnesområden är ofta skiktade på något sätt, ibland i två dimensioner
Alla informationsmodeller blir bättre om de struktureras i ämnesområden. Det är ett enkelt sätt att göra en modell mycket tydligare. Detta finns beskrivet i artiklarna ”10 tips för bättre gestaltning av en informationsmodell” och ”Informationsmodellering – Om ämnesområden”. Sedan behöver även dessa ämnesområden ordnas på något sätt, ofta enligt en skiktning av något slag. Ibland kan det vara fruktbart att ordna den strukturen i två dimensioner. Detta har jag beskrivit i artiklarna ”Om den storskaliga skiktningen av en modell”, och ”Informationsmodellering – Om struktur i flera nivåer”.
- Informationsdomän/Informationsområde
Ofta försöker man dela in informationen i en verksamhet i olika områden eller domäner. Avsikten är att varje område ska kunna ägas och att hanteras var för sig. Indelningen kan baseras på olika saker och skilja sig mycket mellan olika verksamheter. - Begrepp som sträcker sig över flera entiteter
Ibland räcker det inte med att ordna begrepp hierarkiskt, i form av generaliserande entiteter. Det händer att två eller flera entiteter inte har någon gemensam generaliserad entitet men att vi ändå vill se dem som att de tillsammans utgör specialiseringar av något. Världen är inte alltid ordnad efter en enda generaliseringshierarki. Då får vi använda andra sätt att beskriva det än att införa en supertyp.
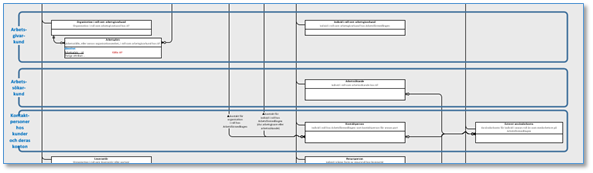
Bild 1: Utsnitt av ER-diagram som visar hur man kan rama in entiteter för att fånga begrepp som man inte vill se som supertyper i en generaliseringshierarki
- Operativt plan – Regelplan
Inom ett ämnesområde kan man ofta dela upp entiteterna i operativa entiteter och de som representerar regler. De operativa har förekomster som beskriver vad som verkligen har hänt i verksamheten, till exempel att man fått en ny kund eller order. De som är regler beskriver vad som är tillåtet. Till exempel vilka kundtyper det finns eller vilken status en kund kan ha.Man kan tänka så här; När man populerar en operativ entitet opererar man verksamheten. När man populerar en entitet som representerar en regel konfigurerar man verksamheten.Hur man delar in en modell, eller ämnesområde, i ett operativt plan och i ett regelplan har jag givit exempel på i artikeln ”Modellmönster – Kundlivscykel – del 2 – Livscykelhändelser”.
- Vad som är obligatoriska data
Vissa attribut är obligatoriska, vilket betyder att de alltid måste ha innehåll. Andra attribut är inte obligatoriska och behöver inte vara fyllda. Oftast markerar vi det i modellen vid attributet på något sätt. Det är också vanligt att relationslinjer har motsvarande symboler för existensregler, det vill säga att relationen alltid måste finnas eller inte behöver finnas.
- Konceptuell – Fysisk
Jag gör alltid modeller som är konceptuella, det vill säga beskriver företeelser och hur de framträder för verksamheten. Eller i varje fall hur jag vill att de ska framträda för verksamheten. Men jag tar oftast med information i modellen om hur de data som representerar dessa företeelser lagras och hanteras fysiskt. Det vill säga tekniska namn, tabellnamn, fältnamn, systemnamn etcetera. Den stora fördelen är att alla känner igen sig och kan använda samma modell. Vi slipper att it-folk lever i en värld, och verksamhetskunniga i en annan. Detta är kanske den enskilt effektivaste åtgärden för att föra samman it och verksamhet. Utan gemensamma kartor kan man inte samarbeta.Ibland handlar det om mer än att man har olika namn på saker och ting. Man kan ha olika strukturer. Men min erfarenhet är att även det går att förmedla i modellen. Se artikeln ”En informationsmodell i stället för flera”. - Schema – Innehåll
Informationsmodeller representerar ju vanligen endast ett schema, det vill säga att man avbildar hur informationen struktureras och inte själva informationen i sig, det vill säga datainnehållet i de strukturer man beskriver.
Men i sammanhang där jag byggt upp data management och behövt analysera en verksamhets data har jag funnit det användbart att bygga på informationsmodellen med beskrivningar av själva datainnehållet. Det kan vara allt från antal förekomster, till högsta och lägsta värdet eller kortaste och längsta text till avvikande och felaktiga värden etcetera. - System
Ofta behöver vi göra en modell över saker som hanteras av flera olika it-system. Då kan vi behöva markera i modellen vilka entiteter som hanteras i vilka system. Ibland har en och samma entitet vissa attribut i ett system och andra attribut i ett annat. Ibland är det värre än så. Det vi vill se som en entitet har förekomster som ligger spridda över flera system. Men det går att hantera i våra modeller om vi är lite kreativa.
- Geografi
Ibland har vi verksamheter som är utspridda över flera länder men som vi ändå behöver hålla ihop i en och samma informationsmodell. De skillnader vi då upptäcker behöver vi kunna beskriva och hantera. Är skillnaderna stora kan man hantera det som flera parallella ämnesområden.
- Organisation
Ibland har vi verksamheter som är spridda på olika grenar, men de är fortfarande så pass lika att vi vill hantera dem inom samma informationsmodell. De skillnader vi då upptäcker behöver vi kunna beskriva och hantera. Även här har jag använt flera parallella ämnesområden.
- Ägarskap
Vi kan behöva markera informationsägarskap i modellen. Vi kanske hoppas på att varje ämnesområde kan ha sin egen ägare, men ofta behöver olika entiteter olika ägare. Kanske också att olika attribut i en och samma entitet har olika ägare. Det förekommer också att olika förekomster av samma entitet behöver ha olika ägare.
Sedan behöver vi egentligen skilja på ägarskap till själva informationen, och ägarskap till det som modellen uttrycker, det vill säga begrepp, terminologi och informationsstruktur.
- Källa för informationen
Ofta behöver vi ange källa för informationen i fråga. Ofta har olika attribut i en och samma entitet olika källor. Vanligen behöver vi hålla reda på hela försörjningskedjan. Vi kanske får informationen från ett internt system, som i sin tur får den från en extern leverantör, som i sin tur har hämtat det från en ursprunglig källa. Det är också vanligt att någon part på vägen knådar om informationen på något sätt. Då bör vi kunna redovisa hur det sker.
- Säkerhetsklassning
Det som slarvigt kallas ”säkerhetsklass” är egentligen tre olika klassningar som behöver göras som inte har mycket gemensamt med varandra, vare sig till orsak eller till åtgärd.- Konfidentialitet: Hur viktigt är det att informationen inte sprids.
- Riktighet: Hur viktigt är det att informationen är korrekt
- Tillgänglighet: Hur viktigt är det att informationen är tillgänglig
- Tidsdimensionen: Tidigare läge – Nuläge – Framtida läge
Ofta gör vi modeller som visar det nuvarande läget. Det är förvånansvärt stabilt, det vill säga det ändrar sig inte så mycket över tiden som man tror, så länge modellen till sin grund är konceptuell.Det som kan ändras är vår förståelse, att vi når en djupare förståelse och behöver uppdatera modellen för att representera den nya förståelsen. Men annars ändras inte en konceptuell modell för att man ändrar enbart tekniken. Det är först då man verkligen utvecklar verksamheten i sig som modellen ändras på riktigt.Det vanligaste för mig är att jag gör konceptuella modeller över nuläget. I nuläget räknar jag in det som är på väg att utvecklas om det är tämligen säkert att det realiseras snart. Men jag brukar då även ta med det som fortfarande finns kvar men som ska avvecklas.
- Versioner av modellen i tiden
Modellen representerar aldrig sanningen utan endast den gemensamma bild vi som varit med har när modellen görs. Men det är även värdefullt att se hur modellen såg ut i ett tidigare stadium, det vill säga att på något sätt kunna följa hur vår förståelse har förändrats över tiden. Kanske vi har skippat ett visst synsätt på vägen. Kanske frågan om det gamla förkastade synsättet kommer upp igen. Då vill vi komma ihåg hur vi resonerade då. Kanske kommer vi vilja gå tillbaka till den tidigare förkastade modellen eller kanske behöver vi uppfriska argumenten från då för att återigen begrava den gamla idén.
- Kommentarer
Modellen ska inte bara påstå saker vi vet utan också vara en plattform för utvecklingen av vår förståelse. Då behöver vi dokumentera hur vi kommit fram till saker, vad vi förkastat och så vidare. Det effektiva sättet är att göra det med är kommentarer. Kommentarerna behöver kunna finnas var som helst i modellens textdel, men behöver tydligt kunna skiljas ut från text som representerar modellen i sig.
Det är inte troligt att vi behöver hantera alla dessa dimensioner på samma gång. Men nästan alla modeller jag gjort och som verkligen har gjort nytta har behövt hantera flera av dessa dimensioner samtidigt.
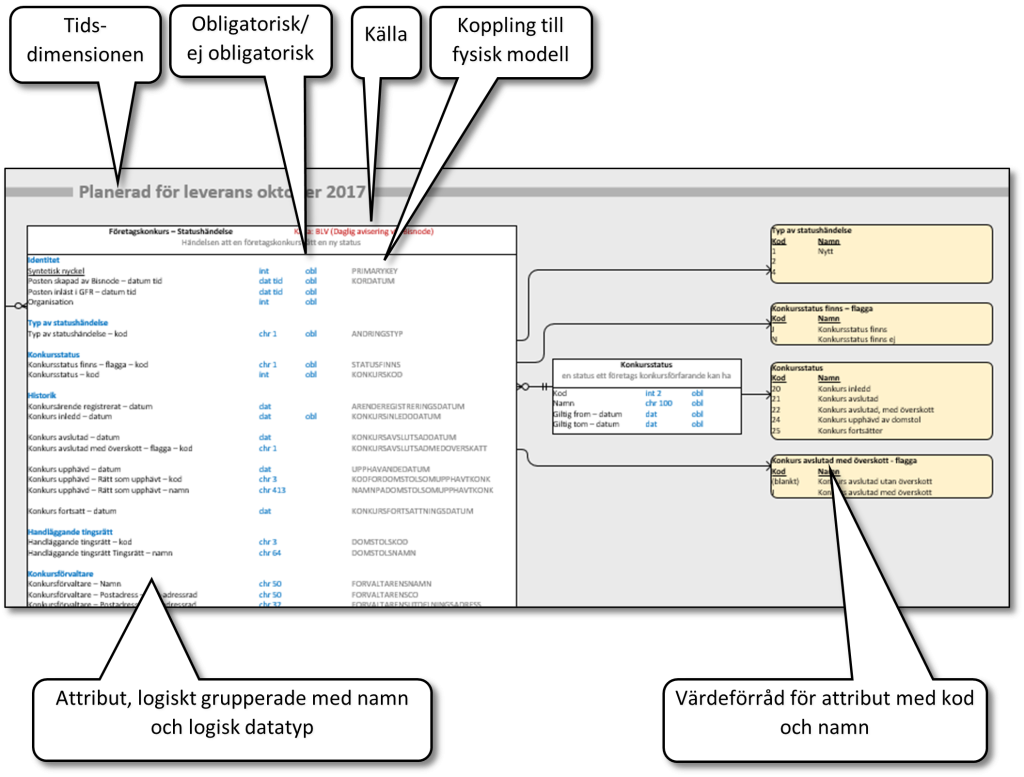
Bild 2: Utsnitt av ER-diagram som exempel på hur man kan få med saker som tidsdimension, datakälla, koppling till fysisk modell och värdeförråd i sitt diagram.
Exempel på modell med många dimensioner
Jag visar i det följande på ett exempel då vi, inspirerade av Tufte, kombinerade ett stort antal dimensioner i samma graf och därmed kunde klargöra komplicerade samband.
Utmaningen
Jag hade ett uppdrag i en koncern verksam inom fintech-området. Koncernen hade genom åren vuxit fram på ett sådant sätt att det var svårt att förstå hur den hängde ihop organisatoriskt. Det fanns olika sätt att se på organisationens struktur. Alla sätt var relevanta i något syfte, men det fanns nästan ingen i organisationen som hade helheten i huvudet. Än mindre kunde någon förklara så att det gick att få en överblick.
Hur skulle man åskådliggöra hur allt detta hängde ihop? Hur skulle man kunna få en gemensam bild som gick att förmedla. Problemet var inte kunskapen i sig. Det fanns beskrivningar av var och ett av perspektiven, men det var som att det inte gick att hantera dessa olika perspektiv tillsammans. Så vår utmaning var att sammanföra de olika strukturerna i en och samma bild så man både kunde se hur de olika strukturerna samverkade både i detalj och som överblick.
Jag beskriver här hur vi gick tillväga i steg för steg för att åskådliggöra strukturen på ett tillgängligt sätt. Vi tog en dimension åt gången och byggde på i en och samma graf.
Dimension 1: Den legala strukturen.
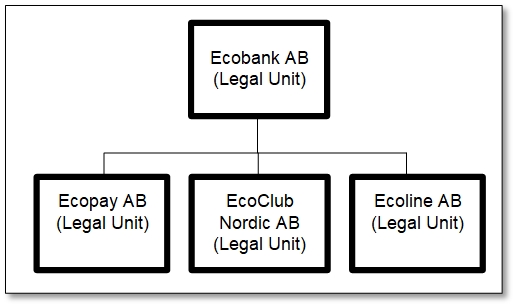
Bild 3: Dimension 1 – Ecobanks legala organisationsstruktur.
Det kändes naturligt att börja med själva koncernstrukturen, vilka de ingående bolagen var och vilket bolag som ägde vilket.
Då fick vi detta enkla schema. Ett moderbolag äger tre dotterbolag.
Observera att ett sånt här schema inte är något annat än ett förekomstdiagram (instansdiagram). Ni som har läst tidigare artiklar vet att jag tycker att det är ett diagram som är en användbar komplettering till de vanliga ER-diagrammen i en informationsmodell. Se artikeln ”Modellera strukturer med instansdiagram”, 2021-06-10.
Dimension 2: Filialstrukturen
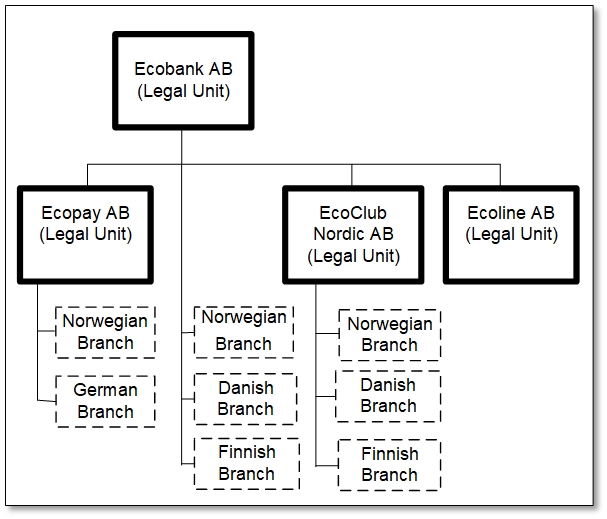
Bild 4: Dimension 2 – Ecobanks interna organisationsstruktur tillagd, i form av vilka EU-filialer man har.
Alla bolagen var svenska men tre av dessa hade filialer i andra länder. Filialerna var inte egna bolag, men hade egna organisationsnummer. På så sätt fick vi hela organisationsstrukturen. Så här långt är strukturen trivial. Men vänta bara, det kommer mera.
Dimension 3: Verksamheter, Dimension 4: Affärsenheter och Dimension 5: Geografi
Koncernen hade två separata verksamheter. Huvudverksamheten drevs av moderbolaget samt två av dotterbolagen, med sina filialer i olika länder. En sidoverksamhet drevs av det tredje dotterbolaget och utan några filialer.
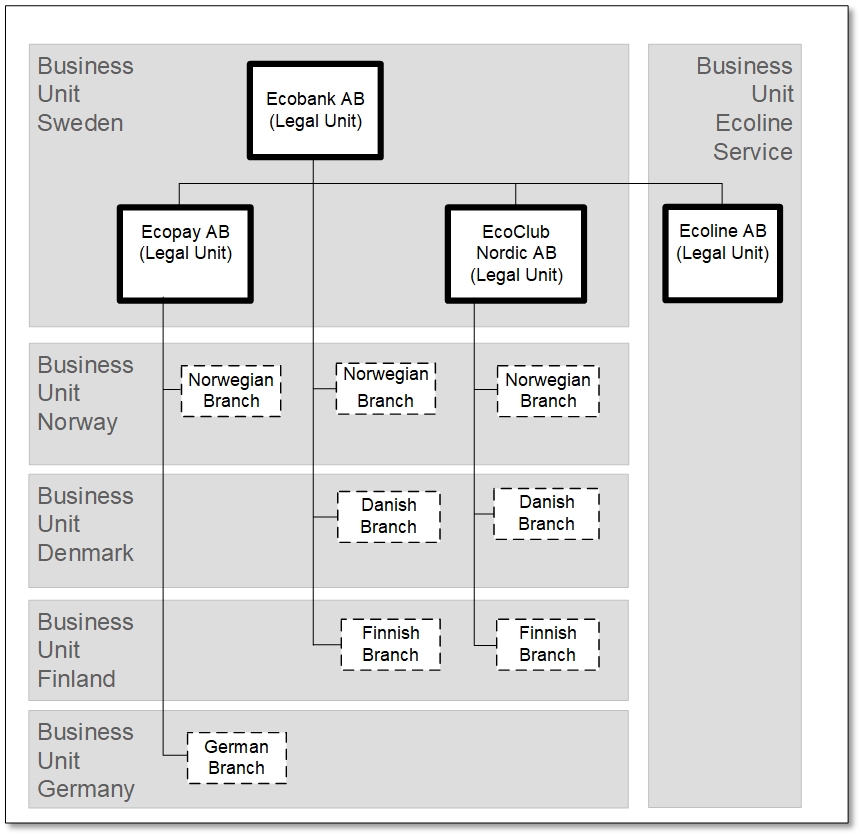
Bild 5: Följande dimensioner är tillagda
– Dimension 3 – Ecobanks två olika typer av verksamheter
– Dimension 4 – Ecobanks indelning i affärsenheter
– Dimension 5 – Ecobanks geografiska struktur
Hela koncernen var indelad i sex affärsenheter (Business Units) enligt bilden. Varje grå yta representerar det man ville se som en egen affärsenhet.
Lägg märke till hur de grå ytorna i grafen är placerade. De ligger som två vertikala spalter där den vänstra spalten med sina tre bolag och sju filialer representerar huvudverksamheten och den högra spalten med sitt bolag representerar sidoverksamheten.
Sedan ligger de grå ytorna i fem horisontella rader, där varje rad representerar ett land där koncernen har verksamhet. Eftersom ett av bolagen, Ecoline AB, har verksamhet i alla de fem länderna sträcker sig den grå ytan vertikalt över alla raderna.
Nu fick vi alltså med både indelningen i två separata verksamheter (de vertikala spalterna), uppdelningen i affärsenheter (de grå ytorna) som var baserad både på verksamhet och på geografi, samt att vi tydliggjorde företagets geografiska struktur (de horisontella raderna).
Dimension 6: Betalningsnätverk och Dimension 7: Varumärken
Huvudverksamheten var tätt kopplad till tre olika internationella betalningsnätverk. Ett av dessa nätverk, här kallat Mpay Network, användes för betalningsprodukter av olika varumärken, varav ett av varumärkena, Mpay Brand, ägdes av ett av dotterbolagen, Ecopay AB. Moderbolaget, Ecobank AB och dotterbolaget, Ecopay AB, delade där på hanteringen av produkter av det varumärket. Ett annat utav betalningsnätverken, Viapay Network, var inte kopplat till något speciellt varumärke och dess produkter hanterades av moderbolaget, och bara i Sverige. Det tredje betalningsnätverket, DC Network, var kopplat till sitt eget varumärke och hanterades av ett av de andra dotterbolagen, EcoClub Nordic AB.
Vi ritade in de tre betalningsnätverken med sina respektive varumärken som streckade rundade rektanglar med olika färg. Eftersom kombinationen nätverk och varumärke var nästan ett-till-ett kunde vi på detta sätt sammanföra dessa två dimensioner till en enda i grafiken.
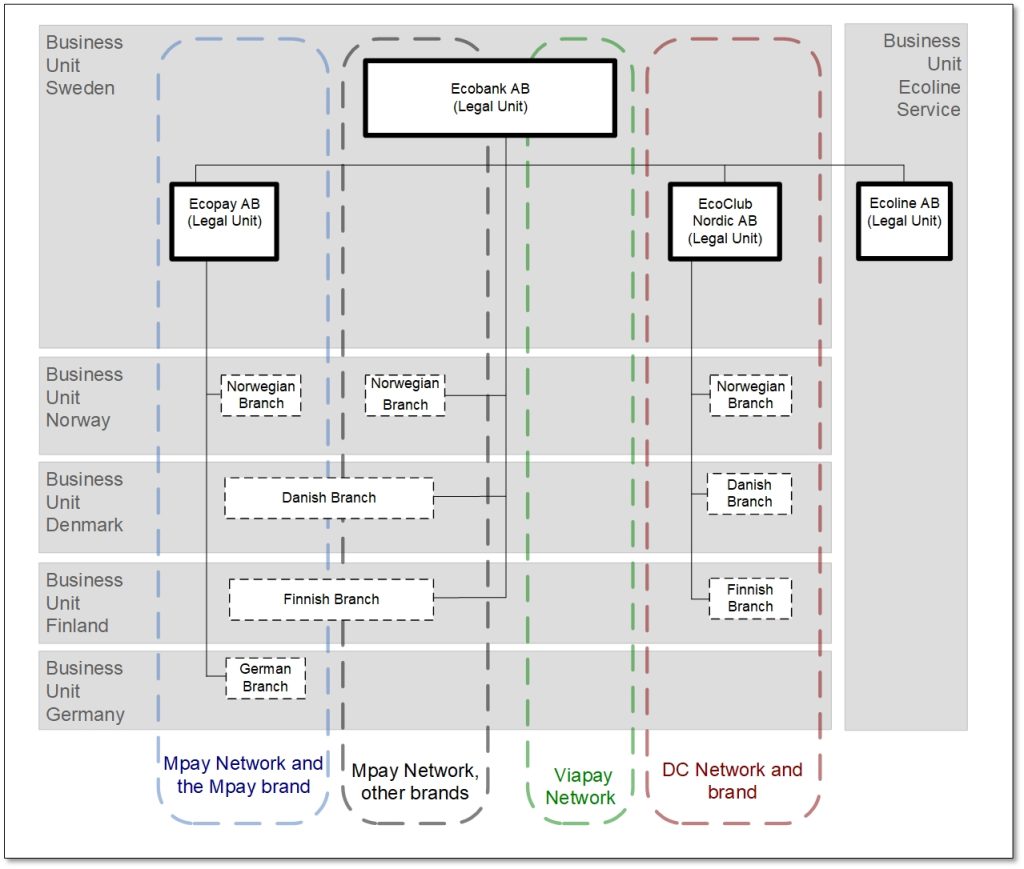
Bild 6: Följande dimensioner tillagda
– Dimension 6 – Ecobanks associerade betalningsnätverk
– Dimension 7 – Varumärken
Dimension 8: Ekonomisk hantering
Koncernen hade en viktig men mycket speciell struktur för den ekonomiska hanteringen. I tidernas begynnelse hade det som nu var filialer varit egna bolag, med sina egna huvudböcker. Senare, när man hade gjorde om de utländska dotterbolagen till filialer, hade man helt enkelt fortsatt med den strukturen för ekonomisk uppföljning. Det blev då att varje bolag och filial hade sin egen ”Unit”. Senare, när man fick behov av att inom ett av bolagen, EcoPay Ab, bokföra transaktioner för betalningsprodukter i valutor utöver den svenska kom man på att man kunde göra det på ett smidigt sätt genom att helt enkelt skapa nya ”Units” för detta. Det var detta som blev fjorton olika ”Units”.
Vi markerade dessa i grafen med gula ovaler invid de bolag och filaler de användes för. Den udda numreringen av dessa var ett arv man hade med sig. För de ”Units” vars syfte var redovisning i andra valutor än den nationella skrev vi vilka valutor de var till för (EUR och GBP).
Resultatet
Resultatet blev som synes en modell i form av ett förekomstdiagram som visar hur verksamheten är organiserad i åtta olika dimensioner. Modellen blev en succé i företaget och började användas i alla möjliga olika sammanhang. För första gången fick man en tydlig och gemensam bild av hur de olika organisatoriska indelningarna egentligen hängde samman. Det vill säga en tydlig gemensam förståelse.
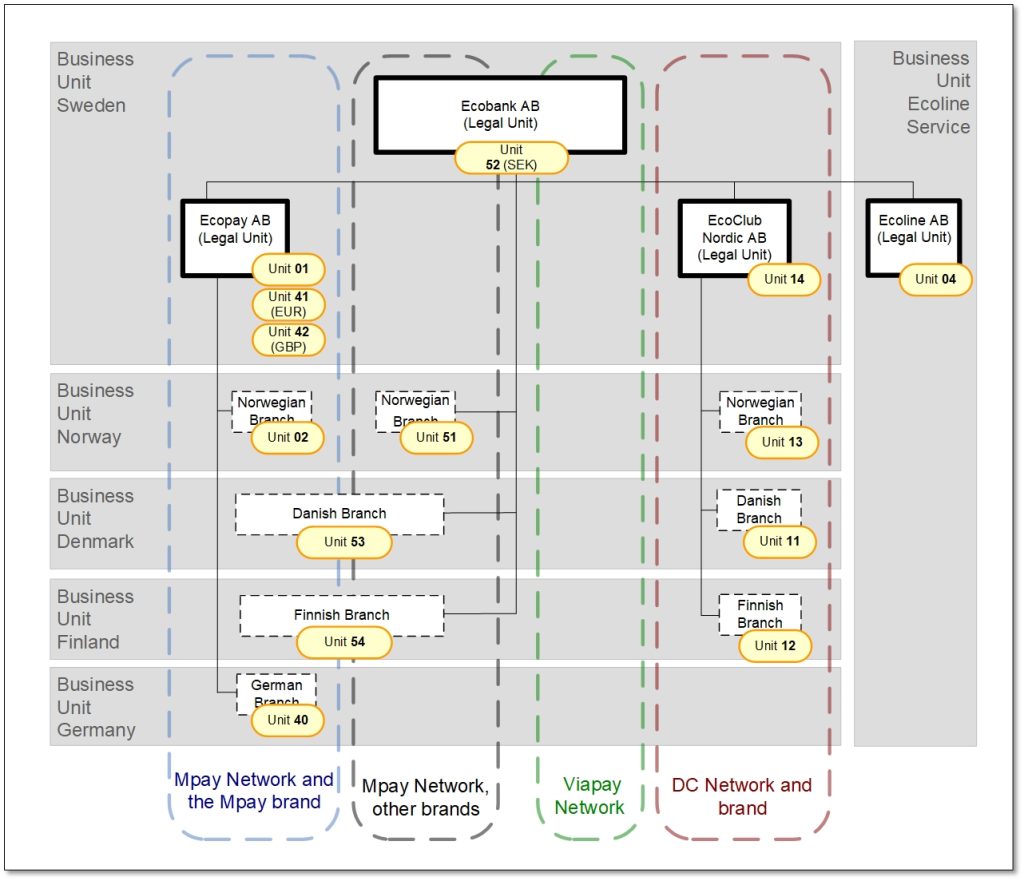
Bild 7: Dimension 8 tillagd – Indelning man har för den ekonomiska hanteringen.
Här kommer mitt ”Call to action”
Det har ofta sagts att man ska hålla modeller enkla så de blir enkla att begripa och underhålla. Med det har man till exempel menat att man inte ska blanda information av olika slag i en och samma modell. En modell ska ge en och endast en vy.
Jag menar, i likhet med Edward Tufte, att detta är helt fel. Vi bör tvärtom se till att våra modeller blir så rika som möjligt, och kombinerar många olika slags information och kunskap.
Visst kan vi fortsätta som förut med våra tunna, närmast anorektiska, modeller. Men det vore verkligen synd om vi som individer och som profession inte utnyttjade den stora potential som informationsmodeller har. Speciellt då i stort sett varje verksamhet är i stort behov av att ta hand om sina data, sina begrepp och sin verksamhetslogik. Och jag menar att vi har de verktyg och den förmåga som krävs. Bara vi ser till att anstränga oss för att bli lite bättre.
Jag tror att vi alla har varit lite för benägna att bara fortsätta och göra som vi har lärt oss, utan att reflektera, utan att fundera på om vi kan bli bättre, utan att våga ifrågasätta och utan att prova nya sätt. Kanske vi har haft alltför stor respekt för det som sagts på kurser och skrivits i böcker. Vi har tänkt: ”Vem är jag att ifrågasätta? Om alla gör på samma sätt så måste det väl vara rätt sätt?”
Men om man tänker på att inget som påstås och lärs ut är för evigt givet utan faktiskt i grunden bara är något som någon hittat på. Då kan vi också ändra på det. Det är bara så som vi kan få utveckling av vårt område. Ty vi behöver ju utveckla vår förmåga att hjälpa våra organisationer att hantera sin komplexitet.
Vad har jag missat?
Du har kanske erfarenheter och idéer för hur vi kan få våra modeller att bli ännu mer användbara.
Eller så har du frågor om allt detta. Hur kan jag göra för att utveckla mina modeller? Hör av dig!
/Peter Tallungs, IRM
Vill du prenumerera på denna artikelserie? Det innebär att du får ett nyhetsbrev, samtidigt som vi publicerar en ny artikel i ämnet informationsarkitektur, med länk till den senaste artikeln. Skriv ett mail till info@irm.se med namn och e-postadress. Skriv IA-artikelserie i ämnesraden.
